9. Hypothesis Testing
9.6 SPSS Lesson 5: Single Sample t-Test
Open “HeadCircum.sav” from the textbook Data Sets:
Look at how simple it is! One variable. This is our single sample. Let’s do a  -test for the hypotheses:
-test for the hypotheses:
![\[H_{0}: \mu = 33.8 \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-07bfeeaf2ae5fe135571cf4eb10e9638_l3.png "Rendered by QuickLaTeX.com")
(9.2) 
where we have used  as the potentially inferred population value. Selecting the value for
as the potentially inferred population value. Selecting the value for  is something that you will need to think about when doing single sample -tests. Some possibilities are: past values, data range midpoints or chance level values. To run the -test in SPSS, pick Analyze
is something that you will need to think about when doing single sample -tests. Some possibilities are: past values, data range midpoints or chance level values. To run the -test in SPSS, pick Analyze  Compare Means One-Sample T Test:
Compare Means One-Sample T Test:
The pop up menu is:

where we have moved our variable into the Test Variable(s) box. If more than one variable is in this box then a separate -test will be run for each variable. The value  has been entered into the Test Value box. That’s how SPSS knows that the hypotheses to test is that of the statement (9.2) above. If you open the Options menus, you will have a chance to specify the associated confidence interval. Running the analysis gives the very simple output:
has been entered into the Test Value box. That’s how SPSS knows that the hypotheses to test is that of the statement (9.2) above. If you open the Options menus, you will have a chance to specify the associated confidence interval. Running the analysis gives the very simple output:
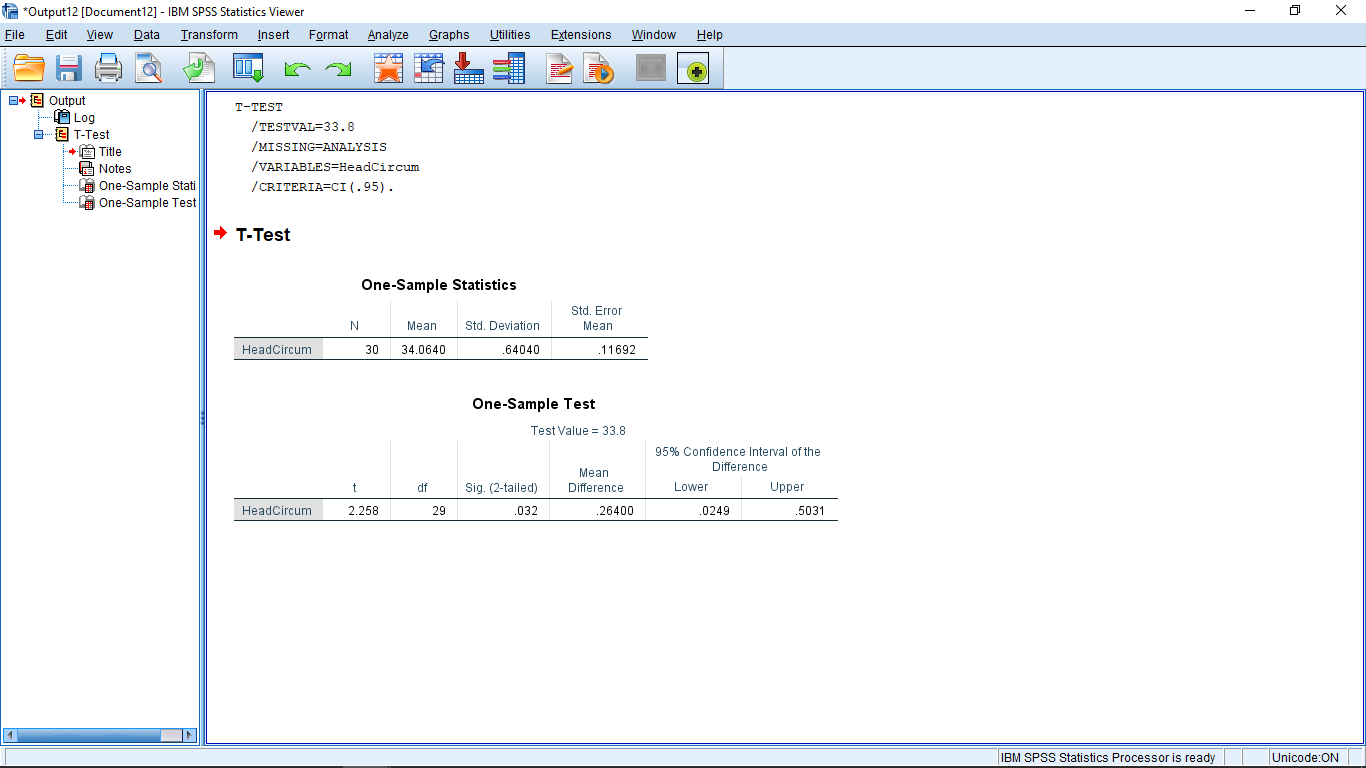
The output is simple but it requires your knowledge of the -test to interpret. As you get more experience with using SPSS, or any canned statistical software, you will get into the habit of looking for the  -value. In SPSS it is in the Sig. (for Significance) column. Here
-value. In SPSS it is in the Sig. (for Significance) column. Here  , which is less than
, which is less than  , so we reject the null hypothesis and conclude that there is evidence that the population mean is not 34.5. Note that this -value is for a two-tailed test. What if you wanted to do a one-tailed test? Well, then you have to think because SPSS won’t do that for you explicitly. For a one-tailed test,
, so we reject the null hypothesis and conclude that there is evidence that the population mean is not 34.5. Note that this -value is for a two-tailed test. What if you wanted to do a one-tailed test? Well, then you have to think because SPSS won’t do that for you explicitly. For a one-tailed test,  , half that of the two-tailed test. Remember that the two-tailed has two tails, each with an area of 0.016 as defined by
, half that of the two-tailed test. Remember that the two-tailed has two tails, each with an area of 0.016 as defined by  , so getting rid of one of those areas gives the for the one- tailed test. Another way to remember to divide the two-tailed by 2 to get the one-tailed value is to remember that people try to go for a one-tailed test when they can because it has more power — it is easier to reject the null hypothesis with a one-tailed test meaning the -value will be smaller for a one-tailed test.
, so getting rid of one of those areas gives the for the one- tailed test. Another way to remember to divide the two-tailed by 2 to get the one-tailed value is to remember that people try to go for a one-tailed test when they can because it has more power — it is easier to reject the null hypothesis with a one-tailed test meaning the -value will be smaller for a one-tailed test.
Let’s look at the rest of the output. There is a lot of redundant information there. You can use that redundant information to check to make sure you know what SPSS is doing and I can use that redundant information to see if you understand what SPSS is doing by reducing the redundancy and asking you to calculate the missing pieces. In the first output table, “One-Sample Statistics” is the information that you would get out of your calculator. The first three columns are  ,
,  and
and  . The last column is
. The last column is  .
.
In the second output table “One-Sample Test”, notice that the test value of 33.8 is printed to remind you what the hypotheses being tested is. Te columns give:  ,
,  , and
, and  . Notice that the first column, is the fourth column divided by the last column of the first table, . The last two columns give the 95% confidence interval
. Notice that the first column, is the fourth column divided by the last column of the first table, . The last two columns give the 95% confidence interval
(9.3) 
Note that zero is not in this confidence interval which is consistent with rejecting the null hypothesis. Simply add  to Equation (9.3) to get the form we go for when we do confidence intervals by hand:
to Equation (9.3) to get the form we go for when we do confidence intervals by hand:
(9.4) 
You can use the output here to compute a further quantity, known as standardized effect size. You’ll get a little practice with doing that in the assignments. The standardized effect size,  , is a purely descriptive statistic (although it can be used in power calculations) and is defined by
, is a purely descriptive statistic (although it can be used in power calculations) and is defined by
(9.5) 
where, by we mean . Being a descriptive statistic, people use the following rule of thumb to describe . If is approximately 0.2 then is considered “small”; if is approximately 0.5 then is considered “medium”; is approximately 0.8 then is considered “large”.
For the presentation of data graphically in reports and papers, an error bar plot is frequently used. To get such a plot for the data here, select Graphs Legacy Dialogs Error Bar:
Choose Simple and “Summaries of separate variables”:
and hit Define. Then set up the menu as follows:
noting that we have chosen “Bars Represent” as “Standard error of the mean” so that the error bars will be  :
:
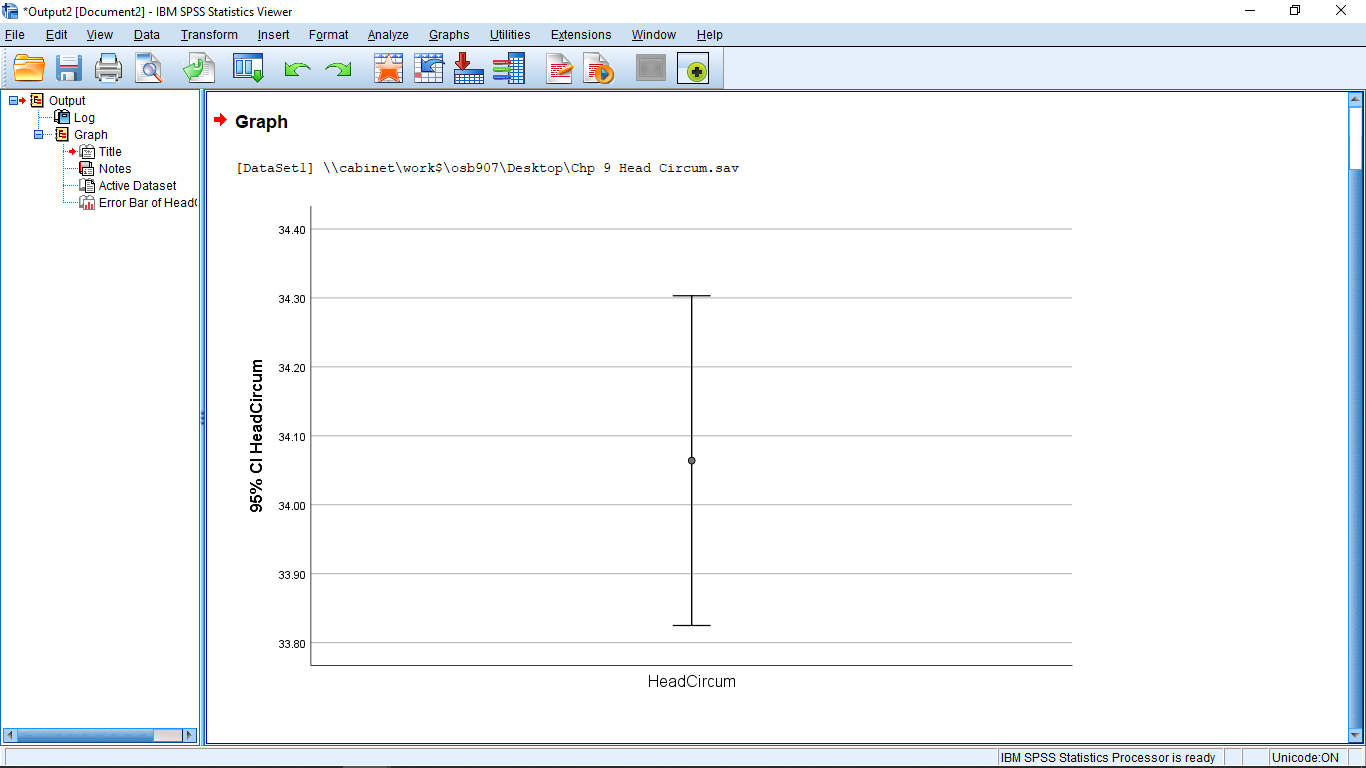
With an error bar plot like this, you can intuitively check the meaning of rejecting  from the formal -test. Here the error bars do not include the value of 33.80 which is consistent with the conclusion that we reject 33.80 as a possible value for the population mean. We can see this more directly, and exactly, if we choose the value 95
from the formal -test. Here the error bars do not include the value of 33.80 which is consistent with the conclusion that we reject 33.80 as a possible value for the population mean. We can see this more directly, and exactly, if we choose the value 95 confidence interval in the Bars Represent pull down of the plot menu.
confidence interval in the Bars Represent pull down of the plot menu.
This is a plot of Equation (9.4). The value is not in the 95% confidence interval.
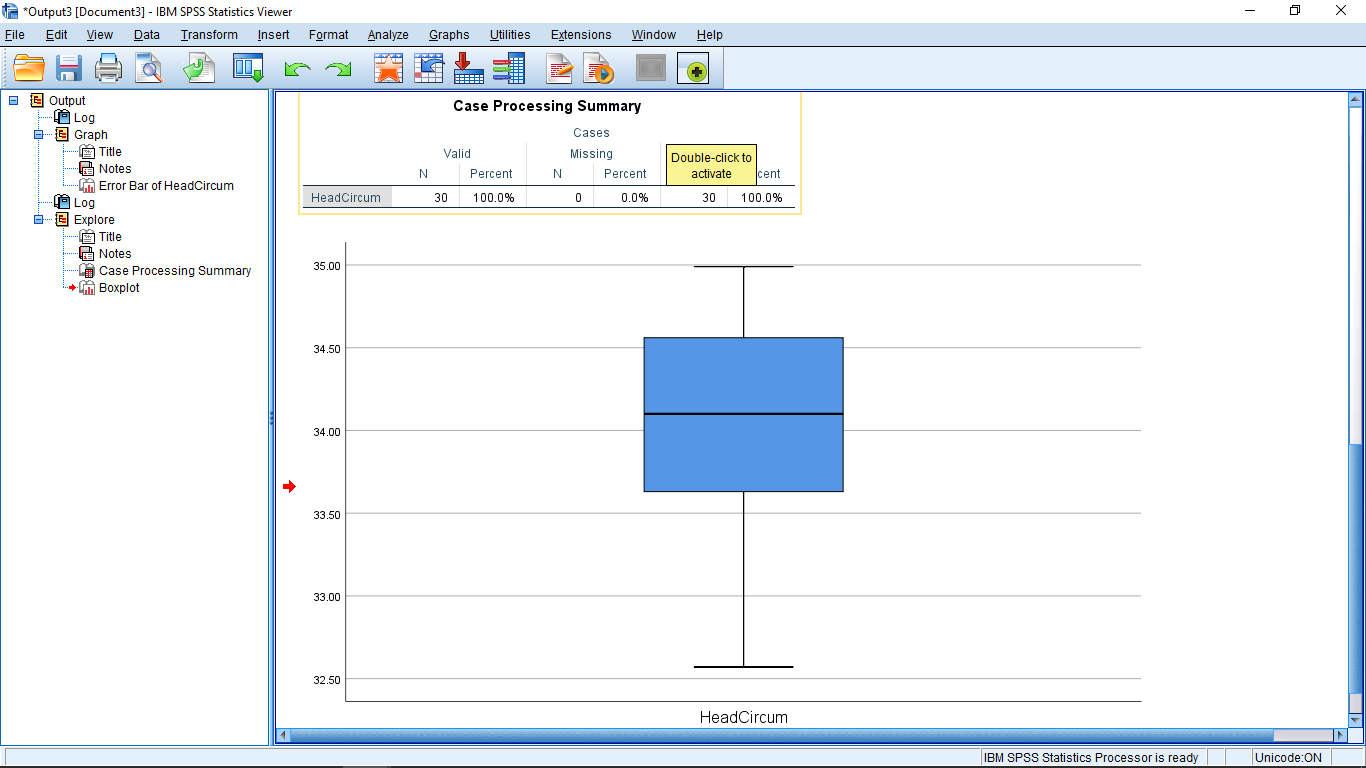
Finally, selecting Graphs Legacy Dialogs Boxplot gives a EDA type of data presentation: