
17. Overview of the General Linear Model
17.1 Linear Algebra Basics
At its most abstract level modern mathematics is based on set theory. Functions,  , are maps that map an element in a domain set,
, are maps that map an element in a domain set,  , to a target,
, to a target,  .
.
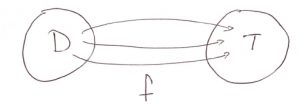
The range of of is the set  , the set of all possible values of . Note that the range is a subset of the target, in set notation symbols:
, the set of all possible values of . Note that the range is a subset of the target, in set notation symbols:  where
where  means subset.
means subset.
17.1.1 Vector Spaces
We specialize immediately to special sets called vector spaces and denote these sets by  . Here
. Here  is the dimension of the vector space. Some examples :
is the dimension of the vector space. Some examples :
 = the set of real numbers = the number line :
= the set of real numbers = the number line :

 = the set of all pairs of real numbers written as a column vector.
= the set of all pairs of real numbers written as a column vector.
![\[ \mathbb{R}^{2} = \left\{ \left. \left( \begin{array}{c} x \\ y \end{array} \right) \; \right| \; x,y \in \mathbb{R} \right\} \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-6ac96135513a4a1f2ab73987d6a29125_l3.png "Rendered by QuickLaTeX.com")
We have introduced some set symbol notation here. The basic notion for a set uses curly brackets with a dividing line:
![\[ \left\{ \mbox{symbols defining the set elements} \mid \mbox{details about the defining set symbols} \right\} \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-58651ac250394c8275809620694c6e88_l3.png "Rendered by QuickLaTeX.com")
The dividing line | is read as “such that”, and the set symbol  is read as “belongs to”, so you would read the set defining above as: “the set of column vectors such that
is read as “belongs to”, so you would read the set defining above as: “the set of column vectors such that  and
and  belong to the set
belong to the set  “.
“.
The transpose of a column vector is an operation written as
![\[ \left( \begin{array}{c} x \\ y \end{array} \right)^{T} = \left( x \;\; y \right) \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-c0d926bb33956e279e498dd0420b3a6d_l3.png "Rendered by QuickLaTeX.com")
…which is known as a row vector. The transpose of a row vector is a column vector.
Continuing with higher dimensions:
![\[ \mathbb{R}^{3} = \left\{ \left. \left( \begin{array}{c} x \\ y \\ z \end{array} \right) \; \right| \; x,y,z \in \mathbb{R} \right\} = \mbox{3D space} \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-998cd114d2c738ea4918f75ae0aad7e0_l3.png "Rendered by QuickLaTeX.com")
In general we have dimensional space[1]:
![\[ \mathbb{R}^{n} = \left\{ \vec{p} = \left. \left( \begin{array}{c} x_{1} \\ x_{2} \\ \vdots \\ x_{n} \end{array} \right) \; \right| \; x_{i} \in \mathbb{R}, \;\; i = 1, 2, \ldots, n \right\} \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-37a17555ecc05abd63cfcb0ed6e37d81_l3.png "Rendered by QuickLaTeX.com")
Notice that we are using the symbol  to abstractly represent a column vector.
to abstractly represent a column vector.
17.1.2 Linear Transformations or Linear Maps
In general we can define maps,  , from
, from  :
:

We will use the following abstract notation for a map:  where
where  ,
,  — gets mapped to
— gets mapped to  by in this example.
by in this example.
A linear map or a linear transformation is a map that abstractly satisfies :
![\[a \ell(\vec{p}) + b \ell(\vec{q}) = \ell(a \vec{p} + b \vec{q})\]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-89f2992752c28fc3e882a529f2408e79_l3.png "Rendered by QuickLaTeX.com")
…where  and
and  (the domain of ). What this statement says is that, for a linear map, it does not matter if you do scalar multiplication and/or vector addition before (in ) or after (in
(the domain of ). What this statement says is that, for a linear map, it does not matter if you do scalar multiplication and/or vector addition before (in ) or after (in  ) the map , the answer will be the same. Scalar multiplication and vector addition[2] are defined as follows, using example
) the map , the answer will be the same. Scalar multiplication and vector addition[2] are defined as follows, using example  :
:
![\[\text{Scalar multiplication: } a \left( \begin{array}{c} x \\ y \\ z \end{array} \right) = \left( \begin{array}{c} ax \\ ay \\ az \end{array} \right)\]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-200246368c8ef7e5e74285060f669036_l3.png "Rendered by QuickLaTeX.com")
![\[\text{Vector addition: } \left( \begin{array}{c} x_{1} \\ y_{1} \\ z_{1} \end{array} \right) + \left( \begin{array}{c} x_{2} \\ y_{2} \\ z_{2} \end{array} \right) = \left( \begin{array}{c} x_{1}+x_{2} \\ y_{1}+y_{2} \\ z_{1}+z_{2} \end{array} \right)\]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-9263d513742d5fec6a553a7cd79f7554_l3.png "Rendered by QuickLaTeX.com")
It turns out that any linear map from to can be represented by an  (rows
(rows  columns) matrix. Let’s look at some examples.
columns) matrix. Let’s look at some examples.
Example 17.1 : A map from to .
![\[ z = \left[ \begin{array}{cc} 1 & 2 \end{array} \right] \left[ \begin{array}{c} x \\ y \end{array} \right] = (1)(x) + (2)(y) \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-54461da1f23557421b571ddc3f574dad_l3.png "Rendered by QuickLaTeX.com")
Here ![\left[ \begin{array}{cc} 1 & 2 \end{array} \right]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-4060f3bb05735e0b086edf94cc9e621f_l3.png "Rendered by QuickLaTeX.com") is a 1 2 matrix that defines a linear map
is a 1 2 matrix that defines a linear map  . The map takes the column vector
. The map takes the column vector ![\left[ \begin{array}{c} x \\ y \end{array} \right]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-2d1fd85a205a7065ae58c379d71ca580_l3.png "Rendered by QuickLaTeX.com") to the number
to the number  in . For example, the vector
in . For example, the vector ![\left[ \begin{array}{c} 2 \\ 3 \end{array} \right]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-d17ac72ebfc3213132cd4dc1c19bc947_l3.png "Rendered by QuickLaTeX.com") gets mapped to 8. Notice how the matrix is applied to the vector. The row of the matrix is is matched to the column of the vector, the numbers are multiplied and then the column added.
gets mapped to 8. Notice how the matrix is applied to the vector. The row of the matrix is is matched to the column of the vector, the numbers are multiplied and then the column added.
▢
Example 17.2 : A map from to .
![\[ \left[ \begin{array}{c} a \\ b \end{array} \right] = \left[ \begin{array}{cc} 1 & 2 \\ 3 & 4 \end{array} \right] \left[ \begin{array}{c} x \\ y \end{array} \right] = \left[ \begin{array}{c} x + 2y \\ 3x +4y \end{array} \right] \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-efc7970ab977500cc846a651feeadffb_l3.png "Rendered by QuickLaTeX.com")
Note that ![\left[ \begin{array}{c} a \\ b \end{array} \right] = \left[ \begin{array}{cc} 1 & 2 \\ 3 & 4 \end{array} \right] \left[ \begin{array}{c} x \\ y \end{array} \right]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-1dbea2718ada05593f489ce511872566_l3.png "Rendered by QuickLaTeX.com") gives us a nice compact way of writing the two equations:
gives us a nice compact way of writing the two equations:

Linear algebra’s major use is to solve such systems of linear equations. Let’s try some numbers in . Say ![\left[ \begin{array}{c} x \\ y \end{array} \right] = \left[ \begin{array}{c} 1 \\ 1 \end{array} \right]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-01183781e1ee02300deccbfc7fed6e44_l3.png "Rendered by QuickLaTeX.com") , then:
, then:
![\[ \left[ \begin{array}{c} a \\ b \end{array} \right] = \left[ \begin{array}{cc} 1 & 2 \\ 3 & 4 \end{array} \right] \left[ \begin{array}{c} 1 \\ 1 \end{array} \right] = \left[ \begin{array}{c} (1)(1)+(2)(1) \\ (3)(1)+(4)(1) \end{array} \right] = \left[ \begin{array}{c} 1+2 \\ 3+4 \end{array} \right] = \left[ \begin{array}{c} 3 \\ 7 \end{array} \right] \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-b365d2aa8e3d0757a74faf6717bafe10_l3.png "Rendered by QuickLaTeX.com")
…so ![\left[ \begin{array}{c} 1 \\ 1 \end{array} \right]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-2fa6dc4ed20c451d528ff236d327bea8_l3.png "Rendered by QuickLaTeX.com") gets mapped to
gets mapped to ![\left[ \begin{array}{c} 3 \\ 7 \end{array} \right]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-7672b612df0d6178deb8caaa89b7f683_l3.png "Rendered by QuickLaTeX.com") .
.
▢
Example 17.3 : A map from  to
to
![\[ \left[ \begin{array}{c} a \\ b \end{array} \right] = \left[ \begin{array}{ccc} 3 & 5 & 9 \\ 2 & 1 & 4 \end{array} \right] \left[ \begin{array}{c} x \\ y \\ z \end{array} \right] = \left[ \begin{array}{c} 3x + 5y + 9z \\ 2x + y + 4z \end{array} \right] \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-582294727b3b1e1a50973c606223c8d4_l3.png "Rendered by QuickLaTeX.com")
Notice that the size of the matrix is 2 3 to give a map from to . Again this is shorthand for

Let’s look at some numbers. Say ![\left[ \begin{array}{c} x \\ y \\ z \end{array} \right] = \left[ \begin{array}{c} 2 \\ 4 \\ 3 \end{array} \right]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-b4ebe608c81d10717d45f69a2d4713f3_l3.png "Rendered by QuickLaTeX.com") , then:
, then:
![\[ \left[ \begin{array}{c} a \\ b \end{array} \right] = \left[ \begin{array}{ccc} 3 & 5 & 9 \\ 2 & 1 & 4 \end{array} \right] \left[ \begin{array}{c} 2 \\ 4 \\ 3 \end{array} \right] = \left[ \begin{array}{c} (3)(2) + (5)(4) + (9)(3)\\ (2)(2) + (1)(4) + (4)(3) \end{array} \right] = \left[ \begin{array}{c} 6 + 20 + 27\\ 4 + 4 + 12 \end{array} \right] = \left[ \begin{array}{c} 53 \\ 20 \end{array} \right] \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-b22e768bc7b65ba2bf48b8e72a99f064_l3.png "Rendered by QuickLaTeX.com")
…so ![\left[ \begin{array}{c} 2 \\ 4 \\ 3 \end{array} \right]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-41b9642e9579ada74e1f499754a4f1e5_l3.png "Rendered by QuickLaTeX.com") gets mapped to
gets mapped to ![\left[ \begin{array}{c} 53 \\ 20 \end{array} \right]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-b5724768534d96ce4e2e172b78f6053b_l3.png "Rendered by QuickLaTeX.com") .
.
▢
Exercises
Compute:
![\[ \left[ \begin{array}{c} a \\ b \end{array} \right] = \left[ \begin{array}{cc} 5 & 2 \\ 1 & 2 \end{array} \right] \left[ \begin{array}{c} 1 \\ 2 \end{array} \right]\]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-1a65d553b4d0bae7c02309cb095a82ef_l3.png "Rendered by QuickLaTeX.com")
![\[ \left[ \begin{array}{c} a \\ b \\ c \end{array} \right] = \left[ \begin{array}{ccc} 10 & 2 & 1 \\ 5 & 1 & 4 \\ 1 & 1 & 1 \end{array} \right] \left[ \begin{array}{c} 2 \\ 3 \\ 2 \end{array} \right]\]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-66860387c9f15f4b377ae57de2dd5cfe_l3.png "Rendered by QuickLaTeX.com")
![\[a = \left[ \begin{array}{ccc} 5 & 7 & 9 \end{array} \right] \left[ \begin{array}{c} 2 \\ 3 \\ 2 \end{array} \right]\]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-d08f1d667c971d69aa2c59a10ad7c935_l3.png "Rendered by QuickLaTeX.com")
17.1.3 Transpose of Matrices
Just like vectors, matrices have a transpose where row and columns are switched. For example
![\[ \left[ \begin{array}{ccc} 1 & 2 & 3 \\ 4 & 5 & 6 \end{array} \right]^{T} = \left[ \begin{array}{cc} 1 & 4 \\ 2 & 5 \\ 3 & 6 \end{array} \right] \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-74b8490df3fd332d1b96dc988b32fff5_l3.png "Rendered by QuickLaTeX.com")
![\[ \left[ \begin{array}{cc} 1 & 2 \\ 1 & 5 \end{array} \right]^{T} = \left[ \begin{array}{cc} 1 & 1 \\ 2 & 5 \end{array} \right] \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-e983ce70766d5fe666288e15c798a0a9_l3.png "Rendered by QuickLaTeX.com")
Note how, for square matrices (where the number of rows is the same as the number of columns), that transpose results in flipping numbers across the diagonal of the matrix.
17.1.4 Matrix Multiplication
An  matrix can be multiplied with a
matrix can be multiplied with a  matrix to give an
matrix to give an  matrix. For example, we can multiply a
matrix. For example, we can multiply a  matrix with a
matrix with a  matrix to give a
matrix to give a  matrix:
matrix:
![\[ \left[ \begin{array}{cc} 2 & 1 \\ 1 & 2 \\ 3 & 1 \end{array} \right] \left[ \begin{array}{ccc} 1 & 2 & 1 \\ 1 & 2 & 1 \end{array} \right] = \left[ \begin{array}{ccc} 3 & 6 & 3 \\ 3 & 6 & 3 \\ 4 & 8 & 4 \end{array} \right] \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-18c43d5b8b3a8f0e96df0273adbb6994_l3.png "Rendered by QuickLaTeX.com")
Notice how the sizes of the matrices match so that the number of columns in the first matrix ( ) matches the number of columns in the second matrix — the ‘s kind of cancel to give the resulting answer.
) matches the number of columns in the second matrix — the ‘s kind of cancel to give the resulting answer.
Matrix multiplication represents a composition of linear maps. In the above example the situation is:

Note that the matrix on the right is applied first. (If you wanted to apply the matrices to a vector in , you would would write the vector on the right.)
When you multiply two square matrices ![[A]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-b2e794eaaca376db17f79ff4fb8089b8_l3.png "Rendered by QuickLaTeX.com") and
and ![[B]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-28b42a6e6a2c07f3ed58ce87b6856f18_l3.png "Rendered by QuickLaTeX.com") (both
(both  ) then, in general,
) then, in general,
![\[ [A] [B] \neq [B][A] \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-5ea4faebab4c84786eec9ad9fa5ca2d6_l3.png "Rendered by QuickLaTeX.com")
Exercises
Compute:
![\[ \left[ \begin{array}{ccc} 1 & 1 & 1 \\ 1 & 2 & 1 \\ 2 & 1 & 2 \end{array} \right] \left[ \begin{array}{ccc} 2 & 1 & 2 \\ 1 & 2 & 3 \\ 3 & 2 & 1 \end{array} \right] \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-ca4987af9a5a764e60d4d1d2b22979d8_l3.png "Rendered by QuickLaTeX.com")
and
![\[ \left[ \begin{array}{ccc} 2 & 1 & 2 \\ 1 & 2 & 3 \\ 3 & 2 & 1 \end{array} \right] \left[ \begin{array}{ccc} 1 & 1 & 1 \\ 1 & 2 & 1 \\ 2 & 1 & 2 \end{array} \right] \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-78ea861f460088288ec62592f09e6a9a_l3.png "Rendered by QuickLaTeX.com")
to see that the results are different.
17.1.5 Linearly Independent Vectors
From an abstract point of view, a set of p vectors
![\[ \vec{x}_{1}, \vec{x}_{2}, \ldots, \vec{x}_{p} \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-e33d54809372be2cb9e71e39fc9ea983_l3.png "Rendered by QuickLaTeX.com")
in are said to be linearly independent if the equation
![\[ c_{1} \vec{x}_{1} + c_{2} \vec{x}_{2} + \cdots + c_{p} \vec{x}_{p} = 0$ \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-e4394c0bdf3e1feef5ec6e09e54d46da_l3.png "Rendered by QuickLaTeX.com")
has only one solution:
![\[ c_{1} = c_{2} = \cdots = c_{p} = 0 \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-3882d746dac7871f721b369dd03360b1_l3.png "Rendered by QuickLaTeX.com")
When vectors are linearly independent, you cannot express one vector as a linear combination of the other vectors. Geometrically (for example in ) :
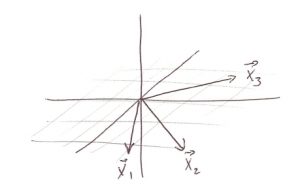
If  ,
,  and
and  are all in the same plane then they are not linearly independent. In that case we could find
are all in the same plane then they are not linearly independent. In that case we could find  and
and  such that
such that  .
.
In an dimensional space it is possible to take, at most, a set of linearly independent vectors.
17.1.6 Rank of a Matrix
Define :
Row rank = the number of linearly independent row vectors in a matrix.
Column rank = the number of linearly independent column vectors in a matrix.
It turns out that:
row rank = column rank = rank
We won’t cover the mechanics of how one calculates the rank of a matrix (take a linear algebra course if you want to know). Instead we just need to understand intuitively what the rank of a matrix means. Consider some simple examples :
Example 17.4 : The  matrix
matrix
![\[ \left[ \begin{array}{cc} 1 & 5 \\ 1 & 5 \end{array} \right] \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-1a4ae876ec45df46675a0a00a304daab_l3.png "Rendered by QuickLaTeX.com")
has rank = 1 because one column is a multiple of the other:
![\[ 5 \left[ \begin{array}{c} 1 \\ 1 \end{array} \right] = \left[ \begin{array}{c} 5 \\ 5 \end{array} \right] \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-625a21d94812ede1c54842b0e69b9890_l3.png "Rendered by QuickLaTeX.com")
▢
Example 17.5 : The  matrix
matrix
![\[ \left[ \begin{array}{cc} 1 & 1 \\ 1 & 2 \end{array} \right] \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-2c444232d2ad40583813e3c9618053ad_l3.png "Rendered by QuickLaTeX.com")
has rank = 2 because there is no way to find such that
![\[ \left[ \begin{array}{c} 1 \\ 2 \end{array} \right] = a \left[ \begin{array}{c} 1 \\ 1 \end{array} \right] = \left[ \begin{array}{c} a \\ a \end{array} \right] \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-5561494e556f4050c7a84228d9de83ce_l3.png "Rendered by QuickLaTeX.com")
▢
Example 17.6 : The matrix
![\[ \left[ \begin{array}{ccc} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array} \right] \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-34dfaa14cf1313f2b36573e512e534ea_l3.png "Rendered by QuickLaTeX.com")
has rank = 3.
▢
Example 17.7 : The matrix
![\[ \left[ \begin{array}{ccc} 1 & 2 & 0 \\ 1 & 2 & 0 \\ 0 & 2 & 1 \end{array} \right] \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-778906a18327be32589e74cd35fa80ca_l3.png "Rendered by QuickLaTeX.com")
has rank = 2 since
![\[ \left[ \begin{array}{c} 2 \\ 2 \\ 2 \end{array} \right] = 2 \left[ \begin{array}{c} 1 \\ 1 \\ 0 \end{array} \right] + 2 \left[ \begin{array}{c} 0 \\ 0 \\ 1 \end{array} \right] \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-fa5a921493015749deb65f179014a213_l3.png "Rendered by QuickLaTeX.com")
▢
17.1.7 The Inverse of a Matrix
For some square matrices ( ) it is possible to find an inverse matrix,
) it is possible to find an inverse matrix, ![[A]^{-1}](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-3c142d676dd72262d0fec57c6f33f425_l3.png "Rendered by QuickLaTeX.com") so that
so that
![\[ [A][A]^{-1} = [A]^{-1} [A] = [I] \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-efdae46f785aec206bc06bad89a98dda_l3.png "Rendered by QuickLaTeX.com")
where ![[I]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-e620fa48094760bf56e357e8b427a43e_l3.png "Rendered by QuickLaTeX.com") is the identity matrix that has 1 on the diagonal and 0 everywhere else.
is the identity matrix that has 1 on the diagonal and 0 everywhere else.
For example, in :
![\[ [I] = \left[ \begin{array}{cc} 1 & 0 \\ 0 & 1 \end{array} \right] \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-4d3b39668f85e332c1974206948c44c7_l3.png "Rendered by QuickLaTeX.com")
In :
![\[ [I] = \left[ \begin{array}{ccc} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array} \right] \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-29b5e7771fdded21d069b8b0551aadc5_l3.png "Rendered by QuickLaTeX.com")
In  :
:
![\[ [I] = \left[ \begin{array}{cccc} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 1 \end{array} \right] \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-e646c0fc5fb4887107bce3ccaa9846b4_l3.png "Rendered by QuickLaTeX.com")
…etc.
Again, we won’t learn how to compute the inverse of a matrix but it is important to know that an matrix will have an inverse if and only if rank![([A]) = n](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-444864c04fcb56958c922d872044688c_l3.png "Rendered by QuickLaTeX.com") .
.
17.1.8 Solving Systems of Equations
In general a system of linear equations can be represented by
![\[\vec{y} = [A] \vec{x}\]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-076aeb995aea4f12a10aa6b4eed5dee6_l3.png "Rendered by QuickLaTeX.com")
where  ,
,  and is an matrix known as the {\em coefficient matrix}. Here
and is an matrix known as the {\em coefficient matrix}. Here  represents the known values and
represents the known values and  represents the unknown values.
represents the unknown values.
There are 3 cases:
 , less equations than unknown. No unique solution.
, less equations than unknown. No unique solution. , number of equations = number of unknowns.
, number of equations = number of unknowns.
- Rank
![[A] < n](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-4625871123d355e5adfdd2d6b3244085_l3.png "Rendered by QuickLaTeX.com") , no unique solution. This is really the same as case 1 because at least one of the equations is redundant.
, no unique solution. This is really the same as case 1 because at least one of the equations is redundant. - Rank
![[A] = n](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-a87f274cc6cd5c860bd44598d11feb80_l3.png "Rendered by QuickLaTeX.com") . This has the unique solution
. This has the unique solution ![\vec{x} = [A]^{-1} \vec{y}](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-925ee8b11134a39e63b9b8a9e95e1325_l3.png "Rendered by QuickLaTeX.com") .
.
 , more equations than unknowns.
, more equations than unknowns.- Rank
![[A] < p](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-0711e6bbf644df9aee52c830951be8ea_l3.png "Rendered by QuickLaTeX.com") , inconsistent formulation, no solution possible.
, inconsistent formulation, no solution possible. - Rank
![[A] = p](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-c11633a6373662e716ae028878fa4d8d_l3.png "Rendered by QuickLaTeX.com") ( is of full rank). A least squares solution is possible and is given by :
( is of full rank). A least squares solution is possible and is given by :
![\[ \vec{x} = ([A]^{T} [A])^{-1} [A]^{T} \vec{y} \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-102026f247a68af495ec069a279c88c5_l3.png "Rendered by QuickLaTeX.com")
That last least squares solution is the punchline to this very quick overview of linear algebra. It is derived using differential calculus in the same way that least squares solutions were derived for linear and multiple regression. The existence of this least squares solution allows us to unify many statistical tests into one big category called the General Linear Model.
- The number will also mean sample size later on because you can organize a data set into a column vector of dimension . In fact, you give SPSS a data vector by entering a column of numbers as a "variable" in the input spreadsheet. ↵
- Abstractly, a vector space is a set where scalar multiplication and vector addition can be sensibly defined. ↵
