
3. Descriptive Statistics: Central Tendency and Dispersion
3.1 Central Tendency: Mean, Median, Mode
Mean, median and mode are measures of the central tendency of the data. That is, as data are collected while sampling from a population, there values will tend to cluster around these measures. Let’s define them one by one.
3.1.1 Mean
The mean is the average of the data. We distinguish between a sample mean and a population mean with the following symbols :
![\[\bar{x} = sample\hspace{.1cm}mean\]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-6ded667e248b7af2a194faaa6690f078_l3.png "Rendered by QuickLaTeX.com")
![\[\mu = population\hspace{.1cm}mean\]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-722f97902c00482f2974b3178a08d6b9_l3.png "Rendered by QuickLaTeX.com")
The formula for a sample mean is :
![\[ \bar{x} = \frac{ \sum_{i=1}^{n} x_{i} }{n} \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-b6ebce3f1eb0a11bfb433acac0a674e1_l3.png "Rendered by QuickLaTeX.com")
where  is the number of data points in the sample, the sample size. For a population, the formula is
is the number of data points in the sample, the sample size. For a population, the formula is
![\[ \mu = \frac{ \sum_{i=1}^{N} x_{i} }{N} \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-16cb66bd565075343c7cdb790dc89171_l3.png "Rendered by QuickLaTeX.com")
where  is the size of the population.
is the size of the population.
Example 3.1 : Find the mean of the following data set :
| 84 | 12 | 27 | 15 | 40 | 18 | 33 | 33 | 14 | 4 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
To illustrate how the indexed symbols that represent the data in the formula work, they have been written below the data values. To get in the habit, let’s organize our data as a table. We will need to do that for more complicated formulae and also that’s how you need to enter data into SPSS, as a column of numbers :
 |
label |
| 84 | |
| 12 | |
| 27 | |
| 15 | |
| 40 | |
| 18 | |
| 33 | |
| 33 | |
| 14 | |
| 4 | |
| Total = 280 |
Since  we have
we have  .
.
☐
Mean for grouped data : If you have a frequency table for a dataset but not the actual data, you can still compute the (approximate) mean of the dataset. This somewhat artificial situation for datasets will be a fundamental situation when we consider probability distributions. The formula for the mean of grouped data is
(3.1) 
where  is the frequency of group
is the frequency of group  ,
,  is the class center of group and is the number of data points in the original dataset. Recall that
is the class center of group and is the number of data points in the original dataset. Recall that  so we can write this formula as
so we can write this formula as
![\[\bar{x} = \frac{ \sum_{i=1}^{G} f_i x_{m_{i}}}{\sum_{i=1}^{G} f_{i}}\]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-ed287dfe6279ad31e9a0461cbafb7a63_l3.png "Rendered by QuickLaTeX.com")
which is a form that more closely matches with a generic weighted mean formula; the formula for the mean of grouped data is a special case of a more general weighted mean that we will look at next. The class center is literally the center of the class — the next example shows how to find it.
Example 3.2 : Find the mean of the dataset summarized in the following frequency table.
| Class | Class Boundaries | Frequency, |
Midpoint, |
 |
| 1 | 5.5 – 10.5 | 1 | 8 | 8 |
| 2 | 10.5 – 15.5 | 2 | 13 | 26 |
| 3 | 15.5 – 20.5 | 3 | 18 | 54 |
| 4 | 20.5 – 25.5 | 5 | 23 | 115 |
| 5 | 25.5 – 30.5 | 4 | 28 | 112 |
| 6 | 30.5 – 35.5 | 3 | 33 | 99 |
| 7 | 35.5 – 40.5 | 2 | 38 | 76 |
| sums | n= = 20 = 20 |
 = 490 = 490 |
Solution : The first step is to write down the formula to cue you to what quantities you need to compute :
![\[\bar{x} = \frac{\sum_{i} f_{i} x_{m_{i}}}{n}\]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-f369d3fde17efe13c6ebef55eb832e00_l3.png "Rendered by QuickLaTeX.com")
We need the sum in the numerator and the value for in the denominator. Get the numbers from the sums of the columns as shown in the frequency table :
![\[\bar{x} = \frac{\sum_{i} f_i x_{m_{i}}}{n} = \frac{490}{20} = 24.5\]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-bc76c429bef9b9ed5367dfe5d6ef0f06_l3.png "Rendered by QuickLaTeX.com")
☐
Note that the grouped data formula gives an approximation of the mean of the original dataset in the following way. The exact mean is given by
![\[\bar{x} = \frac{\sum_{i=1}^{n} x_{i}}{n} = \frac{\sum_{j=1}^{G} (\sum_{k=1}^{f_{i}} x_{k} ) }{n}.\]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-7d6e951bea60529c0c4b382c42bdb3b3_l3.png "Rendered by QuickLaTeX.com")
So the approximation is that
![\[\sum_{k=1}^{f_{i}} x_{k} = f_{i} x_{m_{i}}\]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-b1cc8317f68d48c0bcf1ec37ac4d1312_l3.png "Rendered by QuickLaTeX.com")
which would be exact only if all  in group were equal to the class center .
in group were equal to the class center .
Generic Weighted Mean : The general formula for weighted mean is
(3.2) 
where  is the weight for data point . Weights can be assigned to data points for a variety of reasons. In the formula for grouped data, as a weighted mean, treats the class centers as data points and the group frequencies as weights. The next example weights grades.
is the weight for data point . Weights can be assigned to data points for a variety of reasons. In the formula for grouped data, as a weighted mean, treats the class centers as data points and the group frequencies as weights. The next example weights grades.
Example 3.3 : In this example grades are weighted by credit units. The weights are as given in the table :
| Course | Credit Units, |
Grade,  |
 |
| English | 3 | 80 | 240 |
| Psych | 3 | 75 | 225 |
| Biology | 4 | 60 | 240 |
| PhysEd | 2 | 82 | 164 |
 = 12 = 12 |
 = 297 = 297 |
 = 869 = 869 |
The formula for weighted mean is
![\[\bar{x} = \frac{\sum w_i x_i}{\sum w_i}\]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-df53118dedd0076aadde50999572635a_l3.png "Rendered by QuickLaTeX.com")
so we need two sums. The double bars in the table above separate given data from columns added for calculation purposes. We will be using this convention with the double bars in other procedures to come. Using the sums for the table we get
![\[\bar{x} = \frac{\sum w_i x_i}{\sum w_i} = \frac{869}{12} = 72.4\]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-86c9669ef93780af567dc94dacafd7fa_l3.png "Rendered by QuickLaTeX.com")
Note, that the unweighted mean for these data is
![\[\bar{x} = \frac{\sum x_i}{n} = \frac{297}{4} = 74.3\]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-2deee9d53e0009a00e4bf74569d44e12_l3.png "Rendered by QuickLaTeX.com")
which is, of course, different from the weighted sum.
☐
3.1.2 Median
The symbol we use for median is MD and it is the midpoint of the data set with the data put in order. We illustrate this with a couple of examples :
- If there are an odd number of data points, MD is the middle number.
Given data in order: 180 186 191 201 209 219 220


- If there are an even number of data points, MD is the average of the two middle points :
Given data in order: 656 684 702 764 856 1132 1133 1303

In these examples, the tedious work of putting the data in order from smallest to largest was done for us. With a random bunch of numbers, the work of finding the median is mostly putting the data in order.
3.1.3 Mode
In a given dataset the mode is the data value that occurs the most. Note that :
- it may be there is no mode.
- there may be more than one mode.
Example 3.4 : In the dataset
 , 9, 9, 14, , , 10, 7, 6, 9, 7, , 10, 14, 11, , 14, 11
, 9, 9, 14, , , 10, 7, 6, 9, 7, , 10, 14, 11, , 14, 11
8 occurs 5 times, more than any other number. So the mode is 8.
☐
Example 3.5 : The dataset
110, 731, 1031, 84, 20, 118, 1162, 1977, 103, 72
has no mode. Do not say that the mode is zero. Zero is not in the dataset.
☐
Example 3.6 : The dataset
15,  20, 22,
20, 22,  26, 26
26, 26
has two modes: 18 and 24. This data set is bimodal.
The concept of mode really makes more sense for frequency table/histogram data.
☐
Example 3.7 : The mode of the following frequency table data is the class with the highest frequency.
| Class | Class Boundaries | Freq |
| 1 | 5.5 – 10.5 | 1 |
| 2 | 10.5 – 15.5 | 2 |
| 3 | 15.5 – 20.5 | 3 |
| 4 | 20.5 – 25.5 | 5 (Modal Class) |
| 5 | 25.5 – 30.5 | 4 |
| 6 | 30.5 – 35.5 | 3 |
| 7 | 35.5 – 40.5 | 2 |
☐
3.1.4 Midrange
The midrange, which we’ll denote symbolically by MR, is defined simply by
![\[\mbox{MR} = \frac{H+L}{2}\]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-5fca4a0872fbe2217d9a6176850991d7_l3.png "Rendered by QuickLaTeX.com")
where  and
and  are the high and low data values.
are the high and low data values.
Example 3.8 : Given the following data : 2, 3, 6, 8, 4, 1. We have
![\[\mbox{MR} = \frac{8+1}{2} = 4.5\]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-5c834640b95b264c10cb3dc8a2399cda_l3.png "Rendered by QuickLaTeX.com")
☐
3.1.5 Mean, Median and Mode in Histograms: Skewness
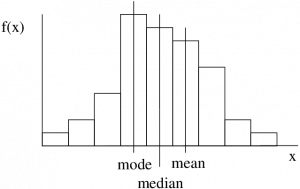
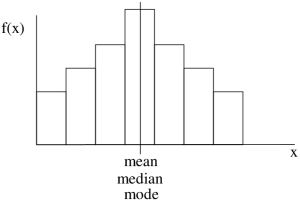
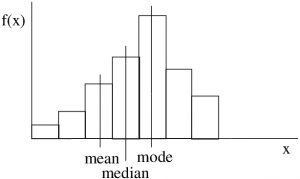
If the shape of the histogram of a dataset is not too bizarre[1] (e.g. unimodal) then we may determine the skewness of the dataset’s histogram (which would be a probability distribution of the data represented a population and not a sample) by comparing the mean or median to the mode. (Always compare something to the mode, no reliable information comes from comparing the median and mean.) If you have SPSS output with the skewness number calculated (we will see the formula for skewness later) then a left skewed distribution will have a negative skewness value, a symmetric distribution will have a skewness of 0 and, a right skewed distribution will have a positive skewness value.
Symmetric distribution
Negatively skewed or left skewed histograms
3.1.6 Mean, Median and Mode in Distributions: Geometric Aspects
To understand the geometrical aspects of histograms we make the abstraction of letting the class widths shrink to zero so that the histogram curve becomes smooth. So let’s consider the mode, median and mean in turn.
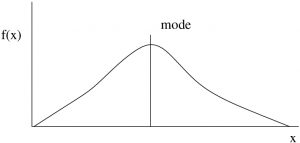
Mode
The mode is the value where the frequency  is maximum, see Figure 3.4. More accurately the mode is a “local maximum” of the histogram[2] (so if there are multiple modes, they don’t all have to have the same maximum value).
is maximum, see Figure 3.4. More accurately the mode is a “local maximum” of the histogram[2] (so if there are multiple modes, they don’t all have to have the same maximum value).
Median
The area under the curve is equal on either side of the median. In Figure 3.5 each area  is the same. For relative frequencies (and so for probabilities) the total area under the curve is one. So the area on each side of the median is half. The median represents the 50/50 probability point; it is equally probable that is below the median as above it.
is the same. For relative frequencies (and so for probabilities) the total area under the curve is one. So the area on each side of the median is half. The median represents the 50/50 probability point; it is equally probable that is below the median as above it.
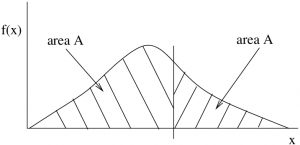 .
.Mean
The mean is the balance point of the histogram/distribution as shown in Figure 3.6.
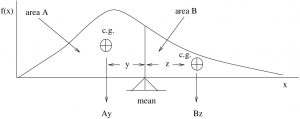
 and
and  balance.
balance.  .
.**A proof that the mean is the center of gravity of a histogram:
In physics, a moment is weight  moment arm :
moment arm :
![\[M = W x\]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-40b15fa522a254ceb93f1487fb2d923e_l3.png "Rendered by QuickLaTeX.com")
where  is moment,
is moment,  is weight and is the moment arm (a distance).
is weight and is the moment arm (a distance).
Say we have two kids, kid1 and kid2 on a teeter-totter (Figure 3.7).
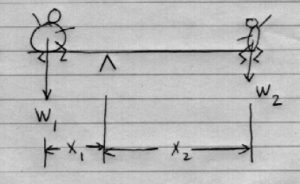
Kid1 with weight  is heavy, kid2 with weight
is heavy, kid2 with weight  is light.
is light.
To balance the teeter-totter we must have
![\[W_{1} x_{1} = W_{2} x_{2}.\]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-2ea37d12cfce721602af21645ffe27a4_l3.png "Rendered by QuickLaTeX.com")
The moment arm, , of the heavier kid must be smaller than the moment arm, , of the lighter kid if they are to balance.
 with corresponding moment arms then the center of gravity (c of g) is the moment arm
with corresponding moment arms then the center of gravity (c of g) is the moment arm  (distance) that satisfies :
(distance) that satisfies : ![\[\sum W_{i} x_{i} = W_{t} x_{g}\]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-49bb11f2f689eab1ed3f4a9696496582_l3.png "Rendered by QuickLaTeX.com")
where  is the total weight.
is the total weight.
With histograms, instead of weight we have area . You can think of area as having a weight. (Think of cutting out a piece of the blackboard with a jigsaw after you draw a histogram on it.) So for a histogram (see Figure 3.8):
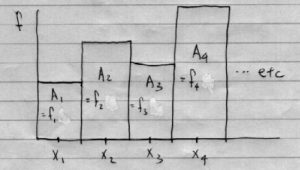
(We assume, for simplicity but “without loss of generality”, that are integers and also the classes. This is the case for discrete probability distributions as we’ll see.) So, for the c of g,
translates to




where we have used  because the class widths are one, so
because the class widths are one, so
![\[x_{g} = \overline{x} = \frac{\sum f_{i} x_{i}}{n}.\]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-10d84810e26a62a96aa2fea493a0f1c9_l3.png "Rendered by QuickLaTeX.com")
Because our “weight” is area,  is technically called the “1st moment of area”. (Variance, covered next, is the “2nd moment of area about the mean”.)
is technically called the “1st moment of area”. (Variance, covered next, is the “2nd moment of area about the mean”.)
◻
 .
. 