
9. Hypothesis Testing
9.2 z-Test for a Mean
This is our first hypothesis test. Use it to test a sample’s mean when :
- The population
 is known.
is known. - Or When
 , in which case use
, in which case use  in the test statistic formula.
in the test statistic formula.
The possible hypotheses are as given in the table you saw in the previous section (one- and two-tailed versions):
| Two-Tailed Test | Right-Tailed Test | Left-Tailed Test |
 : :  |
:  |
:  |
 : :  |
:  |
:  |
In all cases the test statistic is
(9.1) 
In real life, we will never know what the population is, so we will be in the second situation of having to set in the test statistic formula. When you do that, the test statistic is actually a  test statistic as we’ll see. So taking it to be a
test statistic as we’ll see. So taking it to be a  is an approximation. It’s a good approximation but SPSS never makes that approximation. SPSS will always do a -test, no matter how large
is an approximation. It’s a good approximation but SPSS never makes that approximation. SPSS will always do a -test, no matter how large  is. So keep that in mind when solving a problem by hand versus using a computer.
is. So keep that in mind when solving a problem by hand versus using a computer.
Let’s work through a hypothesis testing example to get the procedure down and then we’ll look at the derivation of the test statistic of Equation (9.1).
Example 9.2 : A researcher claims that the average salary of assistant professors is more than $42,000. A sample of 30 assistant professors has a mean salary of $43,260. At  , test the claim that assistant professors earn more than $42,000/year (on average). The standard deviation of the population is $5230.
, test the claim that assistant professors earn more than $42,000/year (on average). The standard deviation of the population is $5230.
Solution :
1. Hypothesis :

 (claim)
(claim)
(This is a right-tailed test.)
2. Critical Statistic.
- Method (a) : Find such that
 from the Standard Normal Distribution Table:
from the Standard Normal Distribution Table:  ; or
; or
- Method (b) : Look up in the t Distribution Table corresponding to one tail (column), and read the last () line:

Method (b) is the recommended method not only because it is faster but also because the procedure for the upcoming -test will be the same for the -test.
3. Test Statistic.
![\[z_{\rm test} = \frac{\bar{x} - k}{\left( \frac{\sigma}{\sqrt{n}}\right)} = \frac{43260 - 42000}{\left( \frac{5230}{\sqrt{30}}\right)} = 1.32\]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-bde55dfa1159cf93149daf0817a84eb1_l3.png "Rendered by QuickLaTeX.com")
4. Decision.
Draw a picture so you can see the critical region :
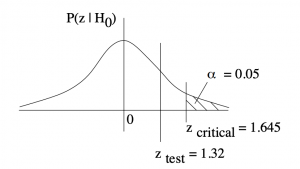
So is in the non-critical region: Do not reject .
5. Interpretation.
There is not enough evidence, from a -test at , to support the claim that professors earn more than $42,000/year on average.
▢
So where does Equation (9.1) come from? It’s an application of the central limit theorem! In Example 9.2,  ,
,  ,
,  and
and  on the null hypothesis of a right-tailed test. The central limit theorem says that if is true then we can expect the sample means,
on the null hypothesis of a right-tailed test. The central limit theorem says that if is true then we can expect the sample means,  to be distributed as shown in the top part of Figure 9.1. Setting means that if the actual sample mean, ends up in the tail of the expected (under ) distribution of sample means then we consider that either we picked an unlucky 5
to be distributed as shown in the top part of Figure 9.1. Setting means that if the actual sample mean, ends up in the tail of the expected (under ) distribution of sample means then we consider that either we picked an unlucky 5 sample or the null hypothesis, , is not true. In taking that second option, rejecting , we are willing to live with the 0.05 probability that we made a wrong choice — that we made a type I error.
sample or the null hypothesis, , is not true. In taking that second option, rejecting , we are willing to live with the 0.05 probability that we made a wrong choice — that we made a type I error.
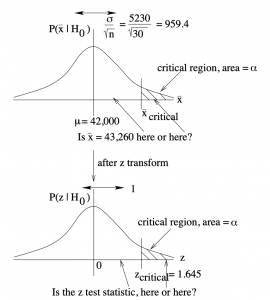 test statistic.
test statistic.Referring to Figure 9.1 again,  on the lower picture defines the critical region of area (in this case). It corresponds to a value
on the lower picture defines the critical region of area (in this case). It corresponds to a value  on the upper picture which also defines a critical region of area . So comparing to on the original distribution of sample means, as given by the sampling theory of the central limit theorem, is equivalent, after -transformation, to comparing
on the upper picture which also defines a critical region of area . So comparing to on the original distribution of sample means, as given by the sampling theory of the central limit theorem, is equivalent, after -transformation, to comparing  with
with  . That is, is the -transform of the data value , exactly as given by Equation (9.1).
. That is, is the -transform of the data value , exactly as given by Equation (9.1).
One-tailed tests
From a frequentist point of view, a one-tailed test is a a bit of a cheat. You use a one-tailed test when you know for sure that your test value or statistic is greater than (or less than) the null hypothesis value. That is, for the case of means here, you know for sure that the mean of the population, if it is different from the null hypothesis mean, if greater than (or less than) the null hypothesis mean. In other words, you need some a priori information (a Bayesian concept) before you do the formal hypothesis test.
In the examples that we will work through in this course, we will consider one-tailed tests when they make logical sense and will not require formal a priori information to justify the selection of a one-tailed test. For a one-tail test to make logical sense, the alternate hypothesis, , must be true on the face value of the data. That is, if we substitute the value of for  into the statement of (for the test of means) then it should be a true statement. Otherwise, is blatantly false and there is no need to do any statistical testing. In any statistical test, must be true at face value and we do the test to see if is statistically true. Another way tho think about this is to think of as a fuzzy number. As a sharp number a statement like “
into the statement of (for the test of means) then it should be a true statement. Otherwise, is blatantly false and there is no need to do any statistical testing. In any statistical test, must be true at face value and we do the test to see if is statistically true. Another way tho think about this is to think of as a fuzzy number. As a sharp number a statement like “ ” may be true, but is fuzzy because of
” may be true, but is fuzzy because of  (think
(think  to get the fuzzy number idea). So “” may not be true when is considered to be a fuzzy number[1]
to get the fuzzy number idea). So “” may not be true when is considered to be a fuzzy number[1]
When we make our decision (step 4) we consider the equality part of the statement in one-tailed tests. This equality is the strict under all circumstances but we use  or
or  is statements simply because they are the logical opposite of
is statements simply because they are the logical opposite of  or
or  in the statements. So people may have an issue with this statement of but we will keep it because of the logical completeness of the , pair and the fact that hypothesis testing is about choosing between two well-defined alternatives.
in the statements. So people may have an issue with this statement of but we will keep it because of the logical completeness of the , pair and the fact that hypothesis testing is about choosing between two well-defined alternatives.
p-Value
The critical statistic defines an area, a probability,  that is the maximum probability that we are willing to live with for making a type I error of incorrectly rejecting . The test statistic also defines an analogous area, called
that is the maximum probability that we are willing to live with for making a type I error of incorrectly rejecting . The test statistic also defines an analogous area, called  or the -value or (by SPSS especially) the significance. The -value represents the best guess from the data that you will make a type I error if you reject . Computer programs compute -values using CDFs. So when you use a computer (like SPSS) you don’t need (or usually have) the critical statistic and you will make your decision (step 4) using the -value associated with the test statistic according to the rule:
or the -value or (by SPSS especially) the significance. The -value represents the best guess from the data that you will make a type I error if you reject . Computer programs compute -values using CDFs. So when you use a computer (like SPSS) you don’t need (or usually have) the critical statistic and you will make your decision (step 4) using the -value associated with the test statistic according to the rule:
![\[ \mbox{If } p\leq \alpha \mbox{ reject } H_{0}.\]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-d0a276011636d94767dbfb60b40eead6_l3.png "Rendered by QuickLaTeX.com")
![\[ \mbox{If } p> \alpha \mbox{ do not reject } H_{0}.\]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-f58f19d81dc44b86c58146b981a1046d_l3.png "Rendered by QuickLaTeX.com")
The method of comparing test and critical statistics is the traditional approach, popular before computers because is is less work to compute the two statistics than it is to compute . When we work problem by hand we will use the traditional approach. When we use SPSS we will look at the -value to make our decision. To connect the two approaches pedagogically we will estimate the -value by hand for a while.
Example 9.3 : Compute the -value for  of Example 9.2.
of Example 9.2.
Solution : This calculation can happen as soon as you have the test statistic in step 3. The first thing to do is to sketch a picture of the -value so that you know what you are doing, see Figure 9.2.
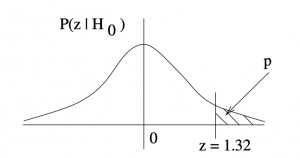 -value associated with
-value associated with  in a one-tail test.
in a one-tail test.Using the Standard Normal Distribution Table to find the tail area associated with , we compute :

That is  . Since
. Since  , we do not reject in our decision step (step 4).
, we do not reject in our decision step (step 4).
▢
When using the Standard Normal Distribution Table to find -values for a given you compute).
- For two-tailed tests:
 . See Figure 9.3.
. See Figure 9.3. - For one-tailed tests:
 (as in Example 9.3)[2].
(as in Example 9.3)[2].
Don’t try to remember these formula, draw a picture to see what the situation is.
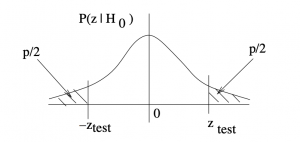 -value associated with a two-tailed . Since is defined by,
-value associated with a two-tailed . Since is defined by,  , is defined by
, is defined by  .
.9.2.1 What p-value is significant?
By culture, psychologists use to define the decision point for when to reject . In that case, if  then it means that the data (the test statistic) indicates there is less than a 5% chance that the result is a statistical fluke; that there is less than a 5% chance that the decision is a Type I error. So, in this course, we assume that unless is otherwise given explicitly for pedagogical purposes. The choice of is actually fairly lax and has led to the inability to reproduce psychological experiments in many cases (about 5% of course). The standards in other scientific disciplines can be different. In particle physics experiments, for example,
then it means that the data (the test statistic) indicates there is less than a 5% chance that the result is a statistical fluke; that there is less than a 5% chance that the decision is a Type I error. So, in this course, we assume that unless is otherwise given explicitly for pedagogical purposes. The choice of is actually fairly lax and has led to the inability to reproduce psychological experiments in many cases (about 5% of course). The standards in other scientific disciplines can be different. In particle physics experiments, for example,  is referred to as “evidence” for a discovery and they must have
is referred to as “evidence” for a discovery and they must have  before an actual discovery, like the discovery of the Higgs boson, is announced. With z test statistics,
before an actual discovery, like the discovery of the Higgs boson, is announced. With z test statistics,  represents the area in the tails of the distribution 3 standard deviations, or
represents the area in the tails of the distribution 3 standard deviations, or  , from the mean. The value
, from the mean. The value  represents tail area
represents tail area  , from the mean. So you may hear physicists saying that they have “5 sigma” evidence when they announce a discovery.
, from the mean. So you may hear physicists saying that they have “5 sigma” evidence when they announce a discovery.
 in the formula for a left tail test.
in the formula for a left tail test. 