
5. The Normal Distributions
5.3 Normal Distribution
Let us now take a detailed look at the normal distribution and learn how to apply it to probability problems (in sampling theory) and statistical problems. Its formula (which you will never have to use because we have tables and SPSS) is again:
(5.28) 
The factor  is a normalization factor that ensures that the area under the whole curve is one:
is a normalization factor that ensures that the area under the whole curve is one:
![\[\int P(x) \: dx = 1.\]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-86f61b67ea77281c1fa343e567a255c6_l3.png "Rendered by QuickLaTeX.com")
Without that factor we just have a bell-shaped curve [1] with the area under the curve equal to one we have a probability function since the total probability is one. For those with a bad math background, the letters in Equation (5.28) are:  [2],
[2],  [3],
[3],  = mean and
= mean and  = standard deviation of the normal distribution. The normal distribution’s shape is as shown in Figure 5.2.
= standard deviation of the normal distribution. The normal distribution’s shape is as shown in Figure 5.2.

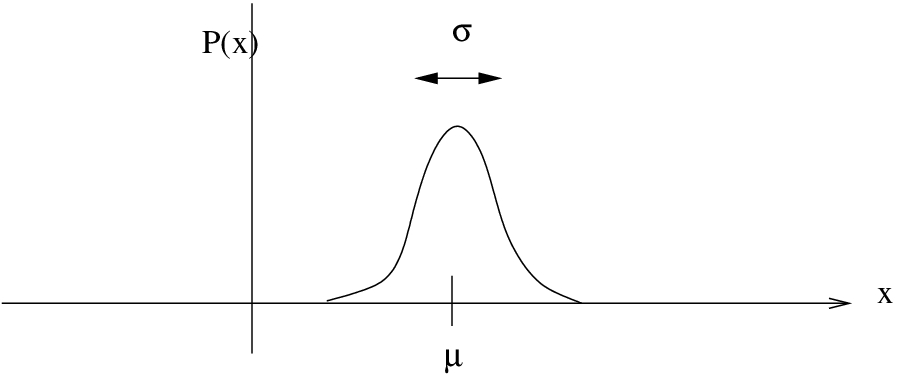
Figure 5.2: The normal distribution. It is a bell-shaped curve with its mode (= mean and median because it’s symmetric,  ) centred on its mean . On the left is a distribution with a large
) centred on its mean . On the left is a distribution with a large  and on the right one with a smaller .
and on the right one with a smaller .
To work with normal distribution, in particular so we can use the Standard Normal Distribution Table and the t Distribution Table in the Appendix, we need to transform it to the standard normal distribution using the  -transform. We need to transform
-transform. We need to transform  , which has a mean and standard deviation to
, which has a mean and standard deviation to  which has a mean of 0 and a standard deviation of 1. Recall the definition of the -transform:
which has a mean of 0 and a standard deviation of 1. Recall the definition of the -transform:
![\[z = \frac{x - \mu}{\sigma}\]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-355df7598ff32d0ae9a791830d67d6ab_l3.png "Rendered by QuickLaTeX.com")
applying this to gives
(5.29) 
If we substitute Equation (5.28) into Equation (5.29) and do the algebra we get :
(5.30) 
Equation (5.30) defines the standard normal distribution, or as we’ll call it, the -distribution.
Areas under are given in the Standard Normal Distribution Table in the Appendix.
5.3.1 Computing Areas (Probabilities) under the standard normal curve
Here we learn how to use the Standard Normal Distribution Table to get probabilities associated with any old area under the normal curve that we can dream up. The general layout of areas under the -distribution is shown in Figures 5.3 and 5.4.
 -distribution is a probability distribution (total area = 1) and symmetric, so the area on either side of the mean (which is 0) is a half. You will need to remember this information as you calculate areas using the Standard Normal Distribution Table.
-distribution is a probability distribution (total area = 1) and symmetric, so the area on either side of the mean (which is 0) is a half. You will need to remember this information as you calculate areas using the Standard Normal Distribution Table.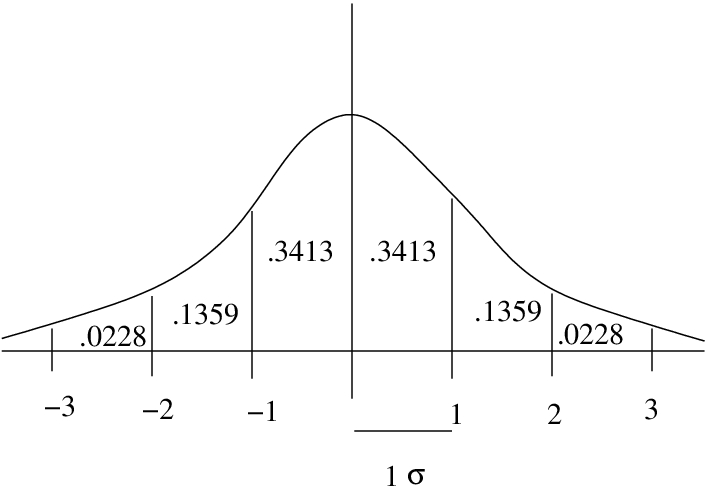 in are standard deviations. No matter what the measurement units of
in are standard deviations. No matter what the measurement units of  were before the -transformation, the units of are “standardized” to be standard deviation units. With SPSS you will learn how to standardize (-transform) variables so that you can sensibly combine multiple dependent variables into one dependent variable for univariate statistical analysis. The areas, probabilities, associated with each increment in are shown here.
were before the -transformation, the units of are “standardized” to be standard deviation units. With SPSS you will learn how to standardize (-transform) variables so that you can sensibly combine multiple dependent variables into one dependent variable for univariate statistical analysis. The areas, probabilities, associated with each increment in are shown here.Let’s divide the types of areas we want to compute into cases, following Bluman[4]. For all these cases we’ll use the notation  to represent the area we look up in the Standard Normal Distribution Table associated with .
to represent the area we look up in the Standard Normal Distribution Table associated with .
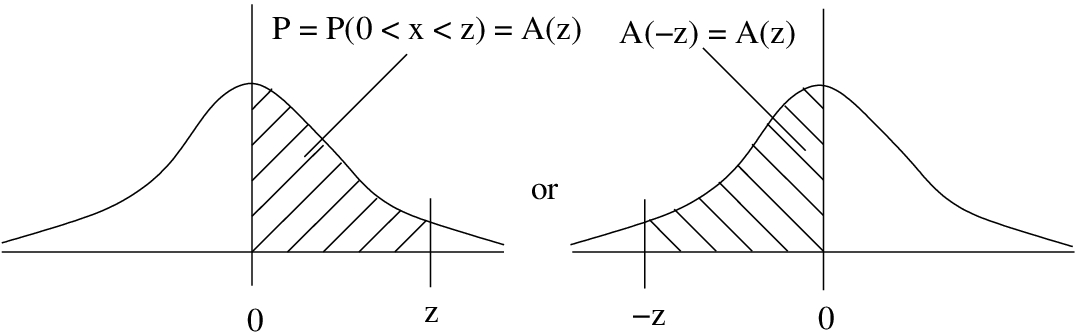
Case 1 : Areas on one side of the mean. This is the case of finding an area between 0 (which corresponds to the mean before any -transformations) and a given . For this case we simply use the tabulated values,  , see Figure 5.5. This case also covers when is a negative number:
, see Figure 5.5. This case also covers when is a negative number:  .
.
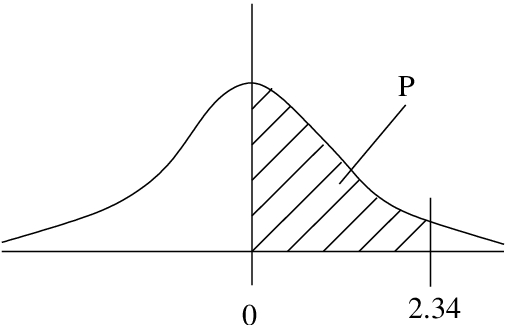
Example 5.1 : Find the probability that is between 0 and 2.34.
Solution : Look up  in the Standard Normal Distribution Table, see Figure 5.6.
in the Standard Normal Distribution Table, see Figure 5.6.  . (Note that it makes no difference whether we use
. (Note that it makes no difference whether we use  or
or  because the probability of a single value is 0. That’s why we need to use areas.)
because the probability of a single value is 0. That’s why we need to use areas.)
▢
Example 5.2 : Find the probability that is between -1.75 and 0.
Solution :  , see Figure 5.7.
, see Figure 5.7.

▢
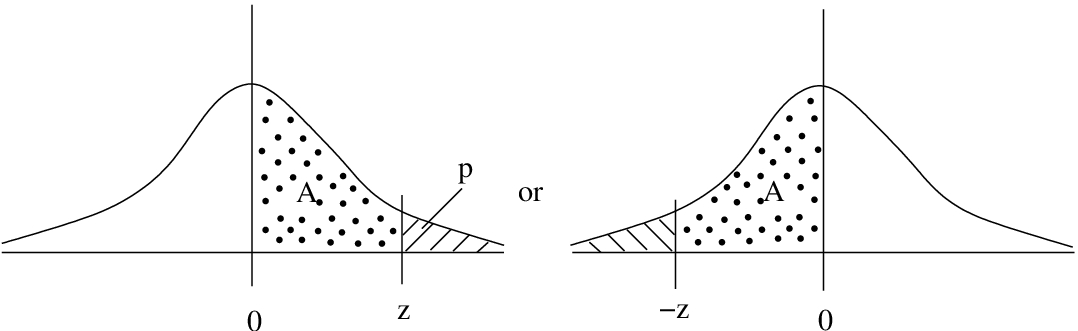
Case 2 : Tail areas. A tail area is the opposite of the area given in the Standard Normal Distribution Table on one half of the normal distribution, see Figure 5.8. The tail area after a given positive is  or before a given negative value
or before a given negative value  is
is  .
.
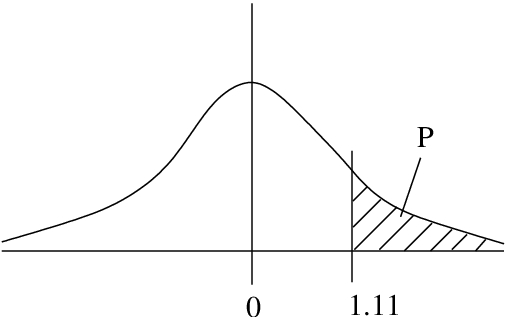
Example 5.3 : What is the probability that  ?
?
Solution :  , see Figure 5.9.
, see Figure 5.9.
▢
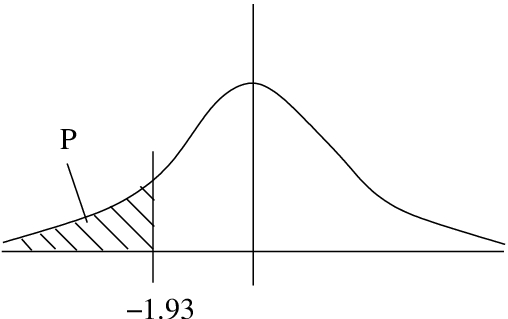
Example 5.4 : What is the probability that  ?
?
Solution :  , see Figure 5.10.
, see Figure 5.10.
▢
Case 3 : An interval on one side of the mean. Recall that  for the -distribution. So we are looking for the probabilities
for the -distribution. So we are looking for the probabilities  for an interval to the right of the mean or
for an interval to the right of the mean or  for an interval to the left of the mean. In either case
for an interval to the left of the mean. In either case  , see Figure 5.11.
, see Figure 5.11.
Example 5.5 : What is the probability that is between 2.00 and 2.97?
Solution :  , see Figure 5.12.
, see Figure 5.12.
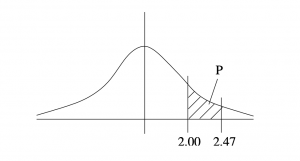
▢
Example 5.6 : What is the probability that is between -2.48 and -0.83?
Solution :  , see Figure 5.13.
, see Figure 5.13.
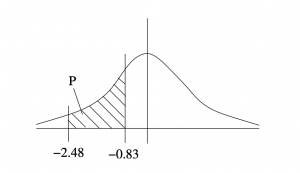
▢
Case 4 : An interval containing the mean. The situation is as shown in Figure 5.14 with the interval being between a negative and a positive number. In that case  .
.
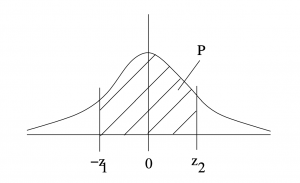
Example 5.7 : What is the probability that is between -1.37 and 1.68?
Solution :  , see Figure 5.15.
, see Figure 5.15.
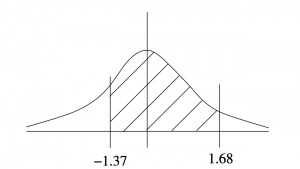
▢
Cases 5 & 6 : Excluding tails. Case 5 is excluding the right tail,  . Case 6 is excluding the left tail,
. Case 6 is excluding the left tail,  . See Figure 5.16. Case 5 is the situation which gives the percentile position of if you multiply the are by 100. More about percentiles in Chapter 6. In either case,
. See Figure 5.16. Case 5 is the situation which gives the percentile position of if you multiply the are by 100. More about percentiles in Chapter 6. In either case,  .
.
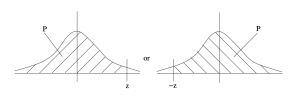
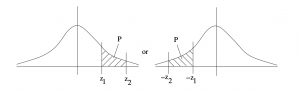
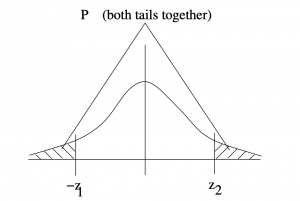
Case 7 : Two unequal tails. In this case we add the areas of the left and right tails, see FIgure 5.17. The special case where the tails have equal areas (i.e. when  in the notation we have been using) is the case we will encounter for two-tail hypothesis testing.
in the notation we have been using) is the case we will encounter for two-tail hypothesis testing.  .
.
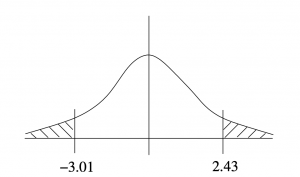
Example 5.8 : Find the areas of the tails shown in Figure 5.18.
Solution :




 .
.
▢
Using the Standard Normal Distribution Table backwards
Up until now we’ve used the Standard Normal Distribution Table directly. For a given , we look up the area . Now we look at how to use it backwards: We have a number that represents the area between 0 and , what is ? Let’s illustrate this process with an example.
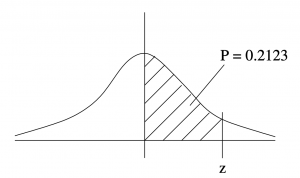
Example 5.9 : We are given an area  as shown in Figure 5.19. What is {z}?
as shown in Figure 5.19. What is {z}?
Solution : Look in the Standard Normal Distribution Table for the closest value to the given  . In this case 0.2123 corresponds exactly to
. In this case 0.2123 corresponds exactly to  .
.
▢
Example 5.9 was artificial in that the given area appeared exactly in the Standard Normal Distribution Table. Usually it doesn’t. In that case pick the nearest area in the table to the given number and use the associated with the nearest area. This, of course, is an approximation. For those who know how, linear interpolation can be used to get a better approximation for .
The -transformation preserves areas
In a given situation of sampling a normal population, the mean and standard deviation of the population are not necessarily 0 and 1. We have just learned how to compute areas under a standard normal curve. How do we compute areas under an arbitrary normal curve? We use the -transformation. If we denote the original normal distribution by and the -transformed distribution by then areas under will be transformed to areas under that are the same. The -transformation preserves areas. So we can compute areas, or probabilities under using the Standard Normal Distribution Table and instantly have the probabilities we need for the original . Let’s follow an example.
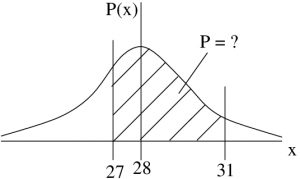
Example 5.10 : Suppose we know that the amount of garbage produced by households follows a normal distribution with a mean of  pounds/month and a standard deviation of
pounds/month and a standard deviation of  pounds/month. What is the probability of selecting a household that produces between 27 and 31 pounds of trash/month?
pounds/month. What is the probability of selecting a household that produces between 27 and 31 pounds of trash/month?
Solution : First convert  and
and  to their -scores:
to their -scores:
![\[ z_{1} = z(27) = \frac{27-28}{2} = \frac{-1}{2} = -0.5 \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-312d03015228bdf7ad1a7a9dc22cc973_l3.png "Rendered by QuickLaTeX.com")
![\[ z_{2} = z(31) = \frac{31-28}{2} = \frac{3}{2} = 1.5 \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-580bf2c1a74495b2c8829f49dbbc82a7_l3.png "Rendered by QuickLaTeX.com")
Then, referring to Figure 5.20, we see that the probability is  .
.
 → z-transform →
→ z-transform →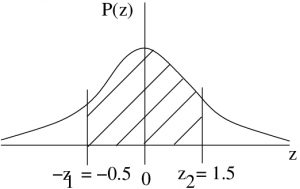
Figure 5.20 : The situation of Example 5.10. Left is the given population, . On the right is the -transformed version of the population . The value 27 is -transformed to -0.5 and 31 is -transformed to 1.5.
▢
In Example 5.10 we used the Standard Normal Distribution Table directly. You will also need to know how to solve problems in which you use this table backwards. The next example shows how that is done. For this kind of problem you will find the first and then you will need to find using the inverse -transformation :
![\[ x = z \cdot \sigma + \mu. \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-34b161da0500e6979bd826e912ad47c0_l3.png "Rendered by QuickLaTeX.com")
which is derived by solving the -transformation,  for .
for .
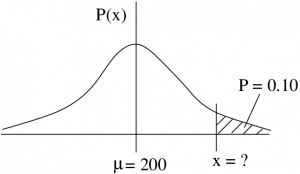
Example 5.11 : In this example we work from given . To be a police person you need to be in the top 10\% on a test that has results that follow a normal distribution with an average of  and
and  .
.
What score do you need to pass?
Solution : First, find the such that  . That is a right tail area (Case 2), so we need
. That is a right tail area (Case 2), so we need  , look at Figure 5.21 to see that. Then, going to the Standard Normal Distribution Table, look for 0.4 in the middle of the table then read off backwards. The closest area is 0.3997 which corresponds to
, look at Figure 5.21 to see that. Then, going to the Standard Normal Distribution Table, look for 0.4 in the middle of the table then read off backwards. The closest area is 0.3997 which corresponds to  . Using the inverse -transformation, convert that to an :
. Using the inverse -transformation, convert that to an :
to get
![\[ x = 1.28 \times 20 + 200 = 25.60 + 200 = 225.60 \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-b1f8aefe0b36b7a6e30e8430fe23b4d4_l3.png "Rendered by QuickLaTeX.com")
or, rounding, use  . There are frequently consequences to our calculations and in this case we want to make sure that we have a score that guarantees a pass. So we round the raw calculation up to ensure that.
. There are frequently consequences to our calculations and in this case we want to make sure that we have a score that guarantees a pass. So we round the raw calculation up to ensure that.
 ← inverse z-transform ←
← inverse z-transform ←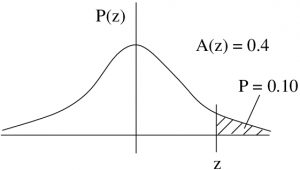
Figure 5.21 : The situation of Example 5.11
▢
- **Whose shape is determined essentially by the shape of
 . Plot
. Plot  and think about the square preventing any negative values for the argument. ↵
and think about the square preventing any negative values for the argument. ↵ - ** The number
 is the natural base implied by functions whose values match how fast it changes, i.e. the derivative of the function is the same as the function. ↵
is the natural base implied by functions whose values match how fast it changes, i.e. the derivative of the function is the same as the function. ↵ - ** Of course,
 comes from circles: = circumference/diameter. ↵
comes from circles: = circumference/diameter. ↵ - Bluman AG, Elementary Statistics: A Step-by-Step Approach, numerous editions, McGraw-Hill Ryerson, circa 2005. ↵
