
12. ANOVA
12.5 Two-way ANOVA
In all the statistical testing we’ve done so far, and will do in Psy 233/234, there is only one dependent variable (DV) — we have been/are doing univariate statistics.
And so far, in all the tests we’ve seen there has only been one independent variable (IV). For the  -tests the IV is group or population with only two values[1] 1 and 2. In one-way ANOVA the single IV has
-tests the IV is group or population with only two values[1] 1 and 2. In one-way ANOVA the single IV has  (number of groups) values. Also, so far, the IV has been a discrete variable (that will change when we get to regression). The graph to keep in mind for the one-way ANOVA is a profile graph as shown in Figure 12.1.
(number of groups) values. Also, so far, the IV has been a discrete variable (that will change when we get to regression). The graph to keep in mind for the one-way ANOVA is a profile graph as shown in Figure 12.1.
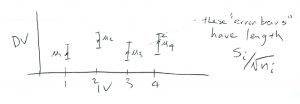
 -axis and the DV on the
-axis and the DV on the  -axis. A one-way ANOVA tests the hypothesis: are all the means
-axis. A one-way ANOVA tests the hypothesis: are all the means  equal to each other? (An actual data profile graph can only have sample values
equal to each other? (An actual data profile graph can only have sample values  , we show a kind of confidence interval plot here.)
, we show a kind of confidence interval plot here.)With two-way ANOVA you have two IVs. Let’s call the two IVs  and
and  . Each IV in two-way ANOVA is called a factor. and can each have several values (or “levels”). To introduce concepts, let’s stick with the case were each of and hove only 2 values:
. Each IV in two-way ANOVA is called a factor. and can each have several values (or “levels”). To introduce concepts, let’s stick with the case were each of and hove only 2 values:  and
and  for , and
for , and  and
and  for . This is the
for . This is the  ANOVA case, where the 2 tells you haw many levels are in each factor. If, for example, had 4 levels (values) and had 3 levels then you’d have a
ANOVA case, where the 2 tells you haw many levels are in each factor. If, for example, had 4 levels (values) and had 3 levels then you’d have a  ANOVA. Let’s stick with the case for now.
ANOVA. Let’s stick with the case for now.
There are several ways to think of a two-way ANOVA. Let’s start with two-dimensional profile plots for a ANOVA :
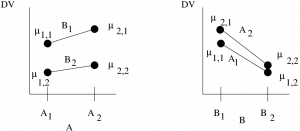
The profile plot can be done in one of two ways. The axis represents the DV in both cases. On the left, the axis represents the IV and the two values of the other IV, , are represented as lines. On the right, the axis represents the IV and the two values of the other IV, , are represented as lines. Look closely at the plots. The dots represent the population values[2] with  being the value of the population labelled by
being the value of the population labelled by  . The means in the two plots are exactly the same. Each combination of IVs,
. The means in the two plots are exactly the same. Each combination of IVs,  , defines a treatment group. For a ANOVA there are four treatment groups.
, defines a treatment group. For a ANOVA there are four treatment groups.
Two way ANOVA supposedly had one of its first applications to agriculture. So, to fix ideas, let’s take our two IV’s, also known as two factors as :

Then, with two levels for each factor, we can visualize the setup as fields where you would grow plants :
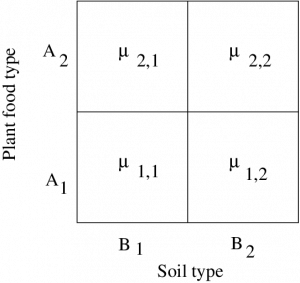
Each field, or treatment group, is also known as a cell.
Now, lets use the and axes to represent the IVs ( and in this case). Then we can use the  axis to represent the DV in a 3D plot :
axis to represent the DV in a 3D plot :
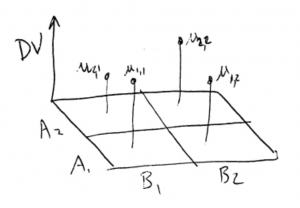
This makes sense. A two-way ANOVA has three variables, two IVs and on DV, so the data are 3D data and the plot above shows how those data appear in 3D space. If you look at the 3D plot from the front you see the profile plot with on the axis. If you look at the 3D plot from the (right) side, you see the profile plot with on the axis.
We’ve focused on designs. But the two IVs can have any number of discrete values or levels. For example, a  cell diagram would look like :
cell diagram would look like :
And a design would look like :
Now that we understand what kind of data we have, it’s time to move onto hypothesis testing. In two-way ANOVA there are three hypotheses to test :
- Is there a “main effect” of ?
- Is there a “main effect” of ?
- Is there an interaction of
 ?
?
In all cases,  is that there is no effect or interaction. As we will see, each hypothesis is a one-way ANOVA of the two-way data suitably collapsed into a one-way design. Let’s begin with the main effect of . The hypothesis is equivalent to collapsing the design across :
is that there is no effect or interaction. As we will see, each hypothesis is a one-way ANOVA of the two-way data suitably collapsed into a one-way design. Let’s begin with the main effect of . The hypothesis is equivalent to collapsing the design across :
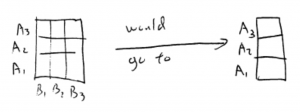
and then doing a one-way ANOVA with the one IV equal to . The collapse is done by averaging over which is the same as removing the cell boundaries between the cells and only categorizing the data by the levels.
The hypothesis for the main effect of is similarly equivalent to collapsing across :

and then doing a one-way ANOVA with the one IV equal to .
The hypothesis test for the interaction is a one-way ANOVA on the “difference of differences”. The idea in interpreting a significant[3] interaction is that the effect of changing IV depends on the effect of changing . Let’s see how the differences arise in a ANOVA :

The interaction tests if there is a significant difference between the two differences  and
and  . Note that I could have set up the differences on the profile plot with on the axis. It does not matter, the resulting one-way ANOVA turns out to be the same. For
. Note that I could have set up the differences on the profile plot with on the axis. It does not matter, the resulting one-way ANOVA turns out to be the same. For  or
or  ANOVAs you get more than two differences to compare with a one-way ANOVA. With a generic
ANOVAs you get more than two differences to compare with a one-way ANOVA. With a generic  ANOVA you need to take a mean of differences to compare to each other. The interpretation of a generic can be tricky.
ANOVA you need to take a mean of differences to compare to each other. The interpretation of a generic can be tricky.
The interpretation of interactions is, however, pretty straightforward. You need to consider all the possible outcome of the ANOVA with its three hypotheses. Since any hypothesis can be significant or not we have  possible outcomes[4]. Let’s look at generic cases of all the combinations of the outcomes of a ANOVA using , and to denote that has been rejected and significant effects have been found :
possible outcomes[4]. Let’s look at generic cases of all the combinations of the outcomes of a ANOVA using , and to denote that has been rejected and significant effects have been found :
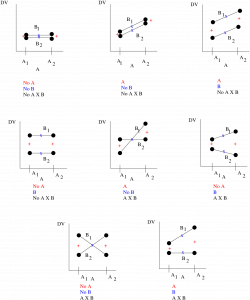
The first thing to remember about these diagrams is that they are for interpretation — for step 5 of our hypothesis testing procedure. You have to do the actual hypothesis test with three  statistics to decide which case you have. Secondly, note that the graphs are generic. In statistics numbers are fuzzy. That is, every mean is fuzzy by a standard deviation. So think of the dots on the graphs as fuzzy balls and that the lines do not have to go to the centers of the fuzzy balls. Now look at the + and x symbols. The + symbols show what happens when you collapse the design over to see the main effect of ; what is left are the two averages[5] for and . The two + means are then compared with a one-way ANOVA (essentially a -test since
statistics to decide which case you have. Secondly, note that the graphs are generic. In statistics numbers are fuzzy. That is, every mean is fuzzy by a standard deviation. So think of the dots on the graphs as fuzzy balls and that the lines do not have to go to the centers of the fuzzy balls. Now look at the + and x symbols. The + symbols show what happens when you collapse the design over to see the main effect of ; what is left are the two averages[5] for and . The two + means are then compared with a one-way ANOVA (essentially a -test since  ) to see if there is a main effect of . Similarly the x symbols show what happens when you collapse the design across to see the main effect of . The means for and will be halfway[6] along the and lines. The two x means are then compared with a one-way ANOVA to see if there is a main effect of . Finally lets look at the interactions. There are four cases in the diagrams that show interactions. In two cases the diagrams have crossed lines where the differences at either end are the negative of each other (and so are different) and in two cases the magnitudes of the differences are different. Looking at all the cases we see that there will be an interaction if the lines are not statistically parallel. The concept of statistically parallel is important here. Your actual data profile plot may not look like it has parallel lines but there will be no significant interaction if the lines are not statistically distinguishable from being parallel — this is the information that the hypothesis test gives you.
) to see if there is a main effect of . Similarly the x symbols show what happens when you collapse the design across to see the main effect of . The means for and will be halfway[6] along the and lines. The two x means are then compared with a one-way ANOVA to see if there is a main effect of . Finally lets look at the interactions. There are four cases in the diagrams that show interactions. In two cases the diagrams have crossed lines where the differences at either end are the negative of each other (and so are different) and in two cases the magnitudes of the differences are different. Looking at all the cases we see that there will be an interaction if the lines are not statistically parallel. The concept of statistically parallel is important here. Your actual data profile plot may not look like it has parallel lines but there will be no significant interaction if the lines are not statistically distinguishable from being parallel — this is the information that the hypothesis test gives you.
Before we move on, let’s consider post-hoc testing for two-way ANOVAs. This usually means comparing means pairwise cell by cell. As with one-way ANOVA that would mean also finding a suitable correction for the  -value if -tests are used. We won’t cover post-hoc testing for two-way ANOVAs in any detail here except to point out that post hoc testing for a
-value if -tests are used. We won’t cover post-hoc testing for two-way ANOVAs in any detail here except to point out that post hoc testing for a  ANOVA is redundant. A ANOVA is essentially three tests. If there is any interesting cell by cell difference, there will be an interaction. With a ANOVA comparing cells is an interpretation problem, not one of statistical testing. The post-hoc test for a ANOVA is really to figure out what generic profile plot matches your data.
ANOVA is redundant. A ANOVA is essentially three tests. If there is any interesting cell by cell difference, there will be an interaction. With a ANOVA comparing cells is an interpretation problem, not one of statistical testing. The post-hoc test for a ANOVA is really to figure out what generic profile plot matches your data.
Next, let’s look at the ANOVA table for a two-way ANOVA. It looks like :
| Source | Sum of Squares | Degrees of Freedom | Mean Square |  |
| A |  |
 |
 |
 |
| B |  |
 |
 |
 |
|
 |
 |
 |
 |
| Within (error) |  |
 |
 |
|
| Totals |  |
N-1 |
The two-way ANOVA table is very similar to the one-way ANOVA table except that there is now one line for each of the three hypotheses (three signals) plus a line that essentially quantifies the noise. We could also add another column for the -value of the three effects. In the degrees of freedom formula,  is the number of levels for the factor and
is the number of levels for the factor and  is the number of levels for the factor. The formula for
is the number of levels for the factor. The formula for  in the table is for a balanced design that has the same number,
in the table is for a balanced design that has the same number,  , of data points in each cell
, of data points in each cell  . The total number of data points in a balanced design is
. The total number of data points in a balanced design is  . For a generic design,
. For a generic design,  and
and  .
.
The formulae in the other columns are the same for any ANOVA table: MS = SS/ for each line, or effect, and
for each line, or effect, and  MS
MS MS
MS . Explicitly:
. Explicitly:
![\[ \mbox{MS}_{A} = \frac{\mbox{SS}_{A}}{\nu_{A}} \;\;\; \;\;\; \mbox{MS}_{B} = \frac{\mbox{SS}_{B}}{\nu_{B}} \;\;\;\; \;\;\; \mbox{MS}_{A \times B} = \frac{\mbox{SS}_{A \times B}}{\nu_{A \times B}} \;\;\;\; \;\;\; \mbox{MS}_{W} = \frac{\mbox{SS}_{W}}{\nu_{W}} \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-53c75de2060ce946974b0a422904d77d_l3.png "Rendered by QuickLaTeX.com")
and the  test statistics are
test statistics are
![\[ F_{A} = \frac{\mbox{MS}_{A}}{\mbox{MS}_{W}} \;\;\;\; \;\;\; F_{B} = \frac{\mbox{MS}_{B}}{\mbox{MS}_{W}} \;\;\;\; \;\;\; F_{A \times B} = \frac{\mbox{MS}_{A \times B}}{\mbox{MS}_{W}}. \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-cf5a4f2b713d1d031ba75bd7cea4ef3b_l3.png "Rendered by QuickLaTeX.com")
For the critical statistics, which you look up in the F Distribution Table, the degrees of freedom to use are  ,
,  ,
,  and
and  .
.
Now all we need are the formulae for the sums of squares. These sums of squares formulae, and the two-way ANOVA that you are responsible for in this class are for a between subjects design. That is, the samples for each cell are independent, every data point is from a different individual. We also assume homoscedasticity,  for all cells . Now to the SS formulae, we’ll just give them for a balanced design[7]. To do this we need to label the data points this way: use
for all cells . Now to the SS formulae, we’ll just give them for a balanced design[7]. To do this we need to label the data points this way: use  where
where  and
and  label the cell (
label the cell ( and
and  ) and labels the data point within the cell (
) and labels the data point within the cell ( )). First we define a “correction term”,
)). First we define a “correction term”,  , to keep the formulae simple:
, to keep the formulae simple:
![\[ C = \frac{1}{N} \left( \sum_{i=1}^{a} \sum_{j=1}^{b} \sum_{k=1}^{n} x_{i,j,k} \right)^{2} \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-fdc29eab350c79363bd50c1a9598b940_l3.png "Rendered by QuickLaTeX.com")
With this, the formulae for the sums of squares in a balanced design two-way ANOVA are:

Relax, you won’t have to chug your way through these sums of squares formulae in an exam. That would be way too tedious even if you are comfortable with all those summation signs. But we will take a look at using them in an example where we set up cell diagrams and use marginal sums to help us along. On an exam, you will be able to simply read the values for the sums of squares from an SPSS ANOVA table output.
Example 12.4 : A researcher wishes to see whether the type of gasoline used and the type of automobile driven have any effect on gasoline consumption. Two types of gasoline, regular and high octane, will be used and two types of automobiles, two-wheel drive and four-wheel drive, will be used in each group. There will be two automobiles in each group for a total of eight automobiles used. The data, in cell form are (the DV is miles per gallon) :
| Type of Automobile (B) | |||
| 2-Wheel | 4-Wheel | ||
| Gas (A) | Regular | 26.7 25.2 |
28.6 29.3 |
| High Octane | 32.3 32.8 |
26.1 24.2 |
|
Using a two-way ANOVA at  test the effects of gasoline and automobile types on gas millage.
test the effects of gasoline and automobile types on gas millage.
Solution :
0.Data Reduction.
Here we will calculate the sums of squares, SS , SS
, SS , SS
, SS and SS (and SS
and SS (and SS ) by hand using marginal sums. Again, in an exam you will be given the sums of squares. But we will see marginal sums again when we do
) by hand using marginal sums. Again, in an exam you will be given the sums of squares. But we will see marginal sums again when we do  contingency tables in Chapter 15.
contingency tables in Chapter 15.

Beginning with the data on the left, sum each cell to give the numbers on the right. In summing each cell you are computing the terms  ,
,  in the sum of squares equations on page 234. (Note that these sums are
in the sum of squares equations on page 234. (Note that these sums are  times the means,
times the means,  , of the cells, which is what the two-way ANOVA compares:
, of the cells, which is what the two-way ANOVA compares:  .) Next, compute the marginal sums, the sums of the rows, on the far right, and the sums of the columns, on the bottom. Then compute the grand sum, the sum of everything, which is the the sum of the marginal sums on the right which equals the sums on the bottoms (which should be equal — a check). The marginal sums show up in the second inner brackets in the sums of squares formula. Notice that the sums of the rows collapse the design across to give a one-way ANOVA for (main effect of ) and the sums of the columns collapse the design across to give a one-way ANOVA for (main effect of ). With the marginal sums we compute:
.) Next, compute the marginal sums, the sums of the rows, on the far right, and the sums of the columns, on the bottom. Then compute the grand sum, the sum of everything, which is the the sum of the marginal sums on the right which equals the sums on the bottoms (which should be equal — a check). The marginal sums show up in the second inner brackets in the sums of squares formula. Notice that the sums of the rows collapse the design across to give a one-way ANOVA for (main effect of ) and the sums of the columns collapse the design across to give a one-way ANOVA for (main effect of ). With the marginal sums we compute:
![\[ C = \frac{1}{N} \left( \sum \sum \sum x_{i,j,k} \right)^{2} = \frac{{225.2}^{2}}{8} = 6339.38 \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-9c05dd00b52d11841723fabda8ca71ea_l3.png "Rendered by QuickLaTeX.com")

![\begin{eqnarray*} \mbox{SS}_{A} & = & \frac{1}{bn} \sum_{i=1}^{a} \left( \sum_{j=1}^{b} \left( \sum_{k=1}^{n} x_{i,j,k} \right) \right)^{2} - C \\ & = & \frac{1}{(2)(2)} \left[ ({109.8})^{2} + ({115.4})^{2} \right] - 6339.38 \\ & = & 6343.30 - 6339.38 \\ & = & 3.92 \end{eqnarray*}](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-9ede21908f98d47278674abdb880e429_l3.png "Rendered by QuickLaTeX.com")
![\begin{eqnarray*} \mbox{SS}_{B} & = & \frac{1}{an} \sum_{j=1}^{b} \left( \sum_{i=1}^{a} \left( \sum_{k=1}^{n} x_{i,j,k} \right) \right)^{2} - C \\ & = & \frac{1}{(2)(2)} \left[ ({117.0})^{2} + ({108.2})^{2} \right] - 6339.38 \\ & = & 6349.06 - 6339.38 \\ & = & 9.68 \end{eqnarray*}](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-9d6a4e64fe51da710847998e3bf6107d_l3.png "Rendered by QuickLaTeX.com")


There. Now the sums of squares are ready for computing the test statistics. At this point you can start making your ANOVA table to keep track of your calculations. Here we’ll see the ANOVA table at the last step.
1. Hypotheses.

2. Critical statistics.
There are three of them, one for each hypothesis pair. Use the F Distribution Table with the  labelling the table equal to the test since there are no such things as one and two tailed tests for ANOVA. From the F Distribution Table find:
labelling the table equal to the test since there are no such things as one and two tailed tests for ANOVA. From the F Distribution Table find:
For :

For :

For :

The critical statistics are all the same for a ANOVA ( for all the hypotheses pairs — essentially three -tests because
for all the hypotheses pairs — essentially three -tests because  ). For bigger designs, the critical statistics will, in general, be different for each hypothesis pair.
). For bigger designs, the critical statistics will, in general, be different for each hypothesis pair.
3. Test statistics.
Use the sums of squares to compute:
![\[ \mbox{MS}_{A} = \frac{\mbox{SS}_{A}}{a-1} = \frac{3.920}{2-1} = 3.920 \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-76360edede2ccd1b41fdeb7be13bb5e7_l3.png "Rendered by QuickLaTeX.com")
![\[ \mbox{MS}_{B} = \frac{\mbox{SS}_{B}}{b-1} = \frac{9.680}{2-1} = 9.680 \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-5188386a0d18d23a1bcccf6016b10e1c_l3.png "Rendered by QuickLaTeX.com")
![\[ \mbox{MS}_{A \times B} = \frac{\mbox{SS}_{A \times B}}{(a-1)(b-1)} = \frac{54.080}{(2-1)(2-1)} = 54.080 \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-a1ffffb3b41bfceb4cc652bc59191739_l3.png "Rendered by QuickLaTeX.com")
![\[ \mbox{MS}_{W} = \frac{\mbox{SS}_{W}}{ab(n-1)} = \frac{3.300}{4} = 0.825 \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-803f1cbc6f95460b39b9374eebb03c50_l3.png "Rendered by QuickLaTeX.com")
![\[ F_{A} = \frac{\mbox{MS}_{A}}{\mbox{MS}_{W}} = \frac{3.920}{0.825} = 4.752 \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-ebed17df39c13022ae943fbd87c1cdc2_l3.png "Rendered by QuickLaTeX.com")
![\[ F_{B} = \frac{\mbox{MS}_{B}}{\mbox{MS}_{W}} = \frac{9.680}{0.825} = 11.773 \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-e99b48c637bd9b46af1059e532ef2fa1_l3.png "Rendered by QuickLaTeX.com")
![\[ F_{A \times B} = \frac{\mbox{MS}_{A \times B}}{\mbox{MS}_{W}} = \frac{54.080}{0.825} = 65.552 \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-185ff93ebfabebf138f7528a87362137_l3.png "Rendered by QuickLaTeX.com")
4. Decision.
In general, we need three diagrams, but in this case all the critical statistics are the same so we can draw :
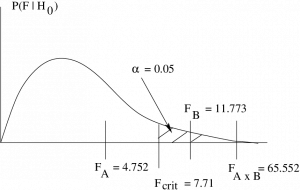
So :
- For , do not reject , there is no main effect of .
- For , reject , there is a main effect of .
- For , reject , there is an interaction.
5. Interpretation.
Simply put, at there is no effect of gas type (factor ) on mileage; there is an effect of auto type (factor ) on gas mileage and; there is an interaction between gas type and mileage, the change in mileage with auto type depends on the gas type used. We’ll look at the profile plot to see if we really understand what this means but first we should complete the ANOVA table :
| Source | Sum of Squares | Degrees of Freedom | Mean Square | |
p |
| (gas) |
3.92 | 1 | 3.92 | |
 |
| (auto) |
9.68 | 1 | 9.68 | |
 |
|
54.08 | 1 | 54.08 |  |
|
| Within (error) | 3.30 | 4 | 0.825 | ||
| Totals | 70.98 | 7 |
To draw the profile plot, we need to do one more data reduction :
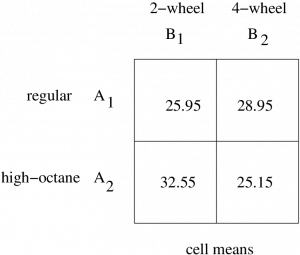
So the profile plot (without error bars — but remember the numbers are fuzzy) is :
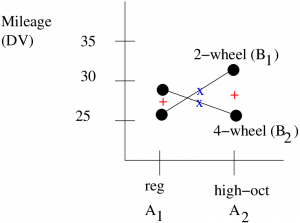
To interpret this fully, remember the rules from previously about collapsing by looking at the midpoints between the two values and the midpoint of the lines. Here we see that averaged over auto types, it looks like there is no difference in gas mileage between gas type. That conclusion is statistically confirmed by the fact that we found no main effect of factor , gas — the two + values are not significantly different. The centres of the lines marked by the x are, however, significantly different because we found a main effect of , auto type. And the nature of the statistically significant interaction is obvious, the gas mileage can go up or down when you change gas types depending on what kind of car you drive. Switching from regular gas to high octane gas will improve your mileage if you drive a 4-wheel drive car but the mileage will get worse if you drive a 2-wheel drive car.
▢
You will see bigger designs than a . Collapsing across or in those larger designs to get to one-way ANOVAs is conceptually straightforward. The interaction is trickier, but the idea of an interaction existing when there are statistically non-parallel lines still holds. The ANOVA is essentially three -tests. This makes the ANOVA powerful and easy to interpret. As always, in statistics simpler is more powerful. We will take a brief quantitative look at statistical power in Chapter 13 but qualitatively, simpler is more powerful.
- For the single sample -test the two values of the IV were the population of interest and a hypothetical population representing having the mean . ↵
- Population values are used for this illustration. When you plot profile plots like this you will use sample means. ↵
- Remember that "significant" means "reject ". ↵
- Remember the counting rule! ↵
- If the cell sizes,
 , are all the same then the average is exactly halfway between the dots. ↵
, are all the same then the average is exactly halfway between the dots. ↵ - For equal cell sizes. For unequal cell sizes the x will still be somewhere along the line. ↵
- Of course, if you're using SPSS you don't need to restrict yourself to a balanced design. SPSS knows the generic SS formulae. ↵
