
12. ANOVA
12.1 One-way ANOVA
A one-way ANOVA (ANalysis Of VAriance) is a generalization of the independent samples  -test to compare more than 2 groups. (Actually an independent samples -test and an ANOVA with two groups are the same thing). The hypotheses to be tested, in comparing the mean of
-test to compare more than 2 groups. (Actually an independent samples -test and an ANOVA with two groups are the same thing). The hypotheses to be tested, in comparing the mean of  groups, with a one-way ANOVA are :
groups, with a one-way ANOVA are :

The following assumptions must be met for ANOVA (the version we have here) to be valid :
- Normally distributed populations (although ANOVA is robust to violations of this condition).
- Independent samples (between subjects).
- Homoscedasticity :
 (ANOVA is robust to violations of this too, especially for larger sample sizes.)
(ANOVA is robust to violations of this too, especially for larger sample sizes.)
The concept of ANOVA is simple but we need to learn some terminology so we can understand how other people talk about ANOVA. Each sample set from each population is referred to as a group or each population is called a group.

There will be groups with sample sizes  ,
,  ,
,  ,
,  with the total number of data points being
with the total number of data points being  . For an ANOVA, the concept of independent variable (IV) and dependent variable (DV) become important (the IV in a single sample or a paired -test is trivially a number like or 0). The groups comprise different values of one IV. The IV is discrete with values or levels.
. For an ANOVA, the concept of independent variable (IV) and dependent variable (DV) become important (the IV in a single sample or a paired -test is trivially a number like or 0). The groups comprise different values of one IV. The IV is discrete with values or levels.
In raw form, the test statistic for a one-way ANOVA is
![\[F_{\rm test} = F_{\nu_{1},\nu_{2}} = \frac{s_{\rm B}^{2}}{s_{\rm W}^{2}}\]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-4db7270ed5e3b2dd9a3d6a1d107b7028_l3.png "Rendered by QuickLaTeX.com")
where
![\[\nu_{1} = k-1 \mbox{ (d.f.N.) \ \ \ } \nu_{2} = N-k \mbox{ (d.f.D.) \ \ \ }\]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-68f610adc7bbbdd13c0e1fc7fbb7f558_l3.png "Rendered by QuickLaTeX.com")
are the degrees of freedom you use when looking up  in the F Distribution Table and where
in the F Distribution Table and where
![\[s_{\rm B}^{2} = \frac{\sum_{i=1}^{k} n_{i} (\bar{x}_{i}- \bar{x}_{\rm GM})^{2}}{k-1}\]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-ce9d2ded0e0c8a7025242bfaef7def97_l3.png "Rendered by QuickLaTeX.com")
is the variance between groups, and
![\[s_{\rm W}^{2} = \frac{\sum_{i=1}^{k}(n_{i}-1) s_{i}^{2}}{\sum_{i=1}^{k}(n_{i}-1)}\]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-9410c9b77c9b23c054393cd477b36e84_l3.png "Rendered by QuickLaTeX.com")
is the variance within groups. Here  ,
,  and
and  are the sample size, mean and standard deviation for sample
are the sample size, mean and standard deviation for sample  and
and  is the grand mean:
is the grand mean:
![\[\overline{x}_{\rm GM} = \frac{\sum_{i=1}^{k}\sum_{j=1}^{n_{i}} x_{ij}}{N} = \frac{\sum_{i=1}^{k} n_{i}\overline{x}_{i}}{N}\]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-d317d94c5cadf5ef1c00a9c2bb91874a_l3.png "Rendered by QuickLaTeX.com")
where  is data point
is data point  in group .
in group .
So you can see that ANOVA, the analysis of variance, is about comparing two variances. The within variance  is the variance of all the data lumped together, just as the grand mean is the mean of all the data lumped together. It is the noise. You can see that the within variance is the weighted mean (weighted by
is the variance of all the data lumped together, just as the grand mean is the mean of all the data lumped together. It is the noise. You can see that the within variance is the weighted mean (weighted by  ) of the group sample variances — a little algebra shows that this is the variance of all the data lumped together. The between variance
) of the group sample variances — a little algebra shows that this is the variance of all the data lumped together. The between variance  a variance of the sample means . It is the signal. If the sample means were all exactly the same then the between variance would be zero. So the higher
a variance of the sample means . It is the signal. If the sample means were all exactly the same then the between variance would be zero. So the higher  the more likely the means are different. is a signal-to-noise ratio. If the means were all the same in the population then would follow a
the more likely the means are different. is a signal-to-noise ratio. If the means were all the same in the population then would follow a  distribution and (whether the population means were the same or not) would follow a
distribution and (whether the population means were the same or not) would follow a  distribution. Thus if the population means were all the same (
distribution. Thus if the population means were all the same ( ) then the
) then the  test statistic follows a
test statistic follows a  distribution which has an expected value[1] (mean) of about 1. must be sufficiently bigger than 1 to reject .
distribution which has an expected value[1] (mean) of about 1. must be sufficiently bigger than 1 to reject .
The analysis of the variances can be broken down further, to sums of squares, with the following definitions[2] :

and

Next we note that  and
and  so
so

and

where

and

so that

Why are sums of squares so prominent in statistics? (They will show up in linear regression too.) Because squares are the essence of variance. Look at the formula for the normal distribution, Equation 5.1. The exponent is a square. Mean and variance are all you need to completely characterize a normal distribution. Means are easy to understand, so sums of square focus our attention to the variance of normal distributions. If we make an assumption that all random noise has a normal distribution (which can be justified on general principles) then the sums of squares will tell the whole statistical story. Sums of squares also tightly links statistics to linear algebra (see Chapter 17) because the Pythagorus Theorem, which gives distances in ordinary geometrical spaces, is about sums of squares.
Computer programs, like SPSS, will output an ANOVA table that breaks down all the sums of squares and other pieces of the test statistic :
| Source | SS |  |
MS | |
 (sig) (sig) |
| Between (signal) | SS |
|
 |
 |
|
| Within (error) | SS |
 |
 |
||
| Totals | SS |
 |
Here is the -value of , reported by SPSS as “sig” for significance. is significant (you can reject ) if  . You should be able to reconstruct an ANOVA table given only the SS values. Notice that the total degrees of freedom of the ANOVA is
. You should be able to reconstruct an ANOVA table given only the SS values. Notice that the total degrees of freedom of the ANOVA is  . One degree of freedom is used up in computing the grand mean, the rest in computing the variances, very similar to how
. One degree of freedom is used up in computing the grand mean, the rest in computing the variances, very similar to how  is the degrees of freedom for sample standard deviation
is the degrees of freedom for sample standard deviation  . If you think of degrees of freedom as the amount of information in the data then the one-way ANOVA uses up all the information in the data. This point will come up again when we consider post hoc comparisons.
. If you think of degrees of freedom as the amount of information in the data then the one-way ANOVA uses up all the information in the data. This point will come up again when we consider post hoc comparisons.
Example 12.1 : A state employee wishes to see if there is a significant difference in the number of employees at the interchanges of three state toll roads. At  is there a difference in the average number of employees at each interchange between the toll roads?
is there a difference in the average number of employees at each interchange between the toll roads?
The data are :
| Road 1 (group 1) | Road 2 (group 2) | Road 3 (group 3) |
| 7 | 10 | 1 |
| 14 | 1 | 12 |
| 32 | 1 | 1 |
| 19 | 0 | 9 |
| 10 | 11 | 1 |
| 11 | 1 | 11 |
Solution :
0. Data reduction.
Using your calculators, find
![\[ n_{1} = 6 \hspace*{3em} \bar{x}_{1} = 15.5 \hspace*{3em} s_{1}^{2} = 81.9 \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-ab0c9b94a024d1de185f8e269e5acb93_l3.png "Rendered by QuickLaTeX.com")
![\[ n_{2} = 6 \hspace*{3em} \bar{x}_{2} = 4.0 \hspace*{3em} s_{2}^{2} = 25.6 \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-f5c121a9fdb5dd8b5ce2ed9fcbf03597_l3.png "Rendered by QuickLaTeX.com")
![\[ n_{3} = 6 \hspace*{3em} \bar{x}_{3} = 5.83 \hspace*{3em} s_{3}^{2} = 29.0 \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-c170704a42eabfe950e2185495f2b654_l3.png "Rendered by QuickLaTeX.com")
 .
.
1. Hypothesis.


2. Critical statistic.
Use the F Distribution Table with  ; do not divide the table
; do not divide the table  (right tail area) by 2 in this case, there are no left and right tail tests in ANOVA. The degrees of freedom needed are
(right tail area) by 2 in this case, there are no left and right tail tests in ANOVA. The degrees of freedom needed are  (d.f.N.) and
(d.f.N.) and  (d.f.D.). With that information
(d.f.D.). With that information
![\[ F_{\rm crit} = 3.68 \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-0ca3b62a5b30b7098c0527c6663cef19_l3.png "Rendered by QuickLaTeX.com")
3. Test statistic.
Compute, in turn :

Note how we saved  and
and  for the ANOVA table. And finally
for the ANOVA table. And finally
![\[ F_{\rm test} = \frac{s_{\rm B}^{2}}{s_{\rm W}^{2}} = \frac{229.59}{45.5} = 5.05 \]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-4719b1f0119dc23422b44a15e6ad80c2_l3.png "Rendered by QuickLaTeX.com")
4. Decision.
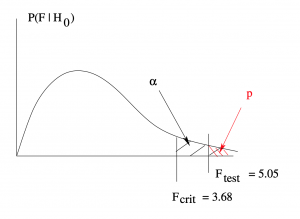
Reject .
5. Interpretation.
Using one-way ANOVA at we found that at least one of the toll roads has a different average number of employees at their interchanges. The ANOVA table is :
| Source | SS | |
MS | |
(sig) |
| Between (signal) | 459.18 | 2 | 229.59 | 5.05 |  |
| Within (error) | 682.5 | 15 | 45.5 | ||
| Totals | 1141.68 | 17 |
We did not compute but a computer program like SPSS will.
▢
 if
if  .
.  . RMS is standard deviation.
. RMS is standard deviation. 