
9. Hypothesis Testing
The process of hypothesis testing can be simplified into :
- Transform (“reduce”) your given data into a test statistic that you can locate on probability distribution given by the sampling theory under a null hypothesis (
 ) about the population. (e.g.
) about the population. (e.g. 
 or
or  test statistic).
test statistic). - See if your test statistic falls into a critical region of the distribution or not. The critical, or rejection region as we’ll call it, represents an area of low probability that the null hypothesis, is true. If the test statistic falls in the rejection region, the we make the decision to reject as the conclusion of the hypothesis test.
Before we define the critical region under the null hypothesis, we need to define what a null hypothesis is. We’ll define two hypotheses, actually, because the null hypothesis needs to contrasted to its logical opposite :
: Null Hypothesis, the hypothesis that nothing is going on; no effect; no signal.
 : Alternative Hypothesis, the hypothesis that is not true; there is an effect; there is a signal.
: Alternative Hypothesis, the hypothesis that is not true; there is an effect; there is a signal.
A good experimental design will be set up so that the effects of interest define . (Your “claim” will be .) Why? It’s about signal to noise ratios. A test statistic is literally signal/noise, a signal to noise ratio. When you do not reject you are saying that there is more noise than signal. When you reject (essentially accepting ) you are saying that there is more signal than noise. Usually you are interested in the signal (also known as an “effect”) so your claim would be . You perform your experiment to find evidence for . If you are interested in noise (can happen, for example to test assumptions on which tests are based) then your claim would be . The examples that follow here don’t follow these experimentally correct rules for which of or should be the claim to emphasize the logical nature of the decision making process. But test statistics are signal to noise ratios and in real life you will be interested in signals.
To fix ideas about hypothesis testing, we’ll first look at hypotheses on the means of populations ( ). Later we’ll consider hypotheses on
). Later we’ll consider hypotheses on  and on
and on  (proportions).
(proportions).
With means there are three combinations of and to consider :
| Two-Tailed Test | Right-Tailed Test | Left-Tailed Test |
:  |
:  |
:  |
:  |
:  |
:  |
Here  is a given number. Not that the rightness or the leftness of the one-tailed test is reflected in . is generally what people are interested in. Then the critical regions, which are on
is a given number. Not that the rightness or the leftness of the one-tailed test is reflected in . is generally what people are interested in. Then the critical regions, which are on  distributions as we’ll see, for each case look like :
distributions as we’ll see, for each case look like :
1. Two-tailed test:
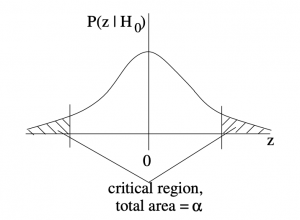
2. Right-tailed test:
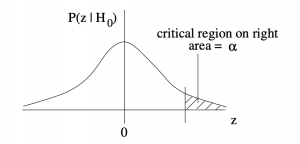
3. Left-tailed test:
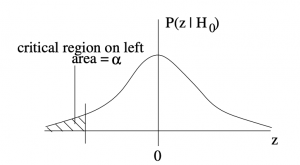
The critical regions, or rejection regions, appear in the probability distributions  , which is the probability distribution that the sample test statistic, , that would occur if were true. These -distributions are -transforms of the distribution of sample means under given by the central limit theorem. More about this when we introduce the formula for the distribution. For now, let’s focus on the decision making process.
, which is the probability distribution that the sample test statistic, , that would occur if were true. These -distributions are -transforms of the distribution of sample means under given by the central limit theorem. More about this when we introduce the formula for the distribution. For now, let’s focus on the decision making process.
When your statistic ends up in the critical region, you conclude that is false. You reject . The critical region is the rejection region.
In the two tailed test, the critical region, with total area  is the opposite to the region
is the opposite to the region  that we have been using for confidence intervals. Compare the two-tail critical region sketch above to Figure 8.1.
that we have been using for confidence intervals. Compare the two-tail critical region sketch above to Figure 8.1.
There are four possible outcomes to a statistical hypothesis test given by the so-called[1] “confusion matrix” :
 true true |
 true true |
|
| Reject (believe ) |
Type I error |
Correct decision 1- |
| Do not reject (believe ) |
Correct decision 1- |
Type II error |
The probabilities are relative to the realities. The probabilities in the columns add to 1. The probability of making a Type I error, , is the area in the critical region. The diagram with the critical region on it assumes that is the reality. We will see how to compute in Chapter 13. The quantity  is defined as the power of the statistical test.
is defined as the power of the statistical test.
We can view the confusion matrix from a medical test point of view. A medical test is a hypothesis test has the following hypotheses pairs :
: negative test result, healthy patient
: positive test result, sick patient
Then :
| Healthy | Sick | |
| Positive Result (believe sick) |
Type I error |
Correct decision 1- |
| Negative Result (believe healthy) |
Correct decision 1- |
Type II error |
In medical tests, the quantity  is known as the test’s specificity, the probability of finding true negatives. The quantity
is known as the test’s specificity, the probability of finding true negatives. The quantity  is the test’s sensitivity, the probability of finding true positives. Generally and are functions of some other decision parameter. In the hypothesis tests that we consider here, is the decision parameter.
is the test’s sensitivity, the probability of finding true positives. Generally and are functions of some other decision parameter. In the hypothesis tests that we consider here, is the decision parameter.
Back to understanding the meaning of hypothesis testing. As we said, a good experimental design will be set up so that is your favourite theory that there is an effect. In that case represents the case that there is no effect : the position of  away from , or away from 0 (in the case of hypothesis testing of ) is just due to noise. If your experiment is then successful in proving your theory, i.e. you reject , then represents the probability that you are wrong. The number actually defines a decision point for rejecting . Later we will see how to compute a value, , that is associated with the test statistic. This -value is then a more refined value for the probability that you are wrong if you reject . From another point of view, would be the probability that your measurement is entirely due to noise.
away from , or away from 0 (in the case of hypothesis testing of ) is just due to noise. If your experiment is then successful in proving your theory, i.e. you reject , then represents the probability that you are wrong. The number actually defines a decision point for rejecting . Later we will see how to compute a value, , that is associated with the test statistic. This -value is then a more refined value for the probability that you are wrong if you reject . From another point of view, would be the probability that your measurement is entirely due to noise.
Let’s do some examples to build our mechanical skills at defining critical regions for distributions.
Example 9.1 : Critical Areas on -distributions with hypothesis testing on the mean, .
(a) Left-tailed test with  . Find the critical value
. Find the critical value  .
.
First step, draw a picture :
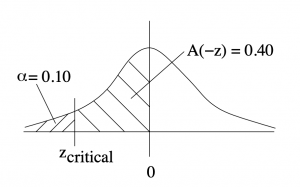
With the tables we have in the Appendix, there are two ways to find :
-
- Method (a) : Look up area in the Standard Normal Distribution Table equal to 0.40 : Closest is 1.28 so
 .
. - Method (b) : Use the last line in the t Distribution Table for the one tailed test column. Find a of 1.282 and add a minus sign because we have a left tail test. So
 .
.
- Method (a) : Look up area in the Standard Normal Distribution Table equal to 0.40 : Closest
Use Method (b) on tests and exams. It is faster, requires less thinking about areas (and so less chance for making a mistake) and gives a slightly more accurate result. The critical area or critical region or the rejection region is where  . The critical value that defines the region in this case is
. The critical value that defines the region in this case is  .
.
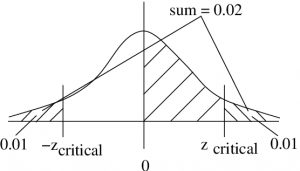
(b) A two tailed test with  . Find the critical value .
. Find the critical value .
Draw a picture :
-
- Method (a) : Look up area in the Standard Normal Distribution Table equal to 0.49. The closest is 2.33. So, because we have a two-tailed test,
 .
. - Method (b): Use the last line in the t Distribution Table, for two tailed test, . Find
 ,
,  .
.
- Method (a) : Look up area in the Standard Normal Distribution Table equal to 0.49. The closest
Again, Method (b) is the recommended approach.
So the critical areas are those where
![\[ z > 2.326 \mbox{ and } z < -2.326\]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-894f374e4cb4ad03ba1e270190b91cf5_l3.png "Rendered by QuickLaTeX.com")
and the critical values are  and
and  .
.
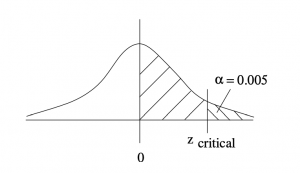
(c) A right tailed test with  . Find the critical value .
. Find the critical value .
Draw a picture :
-
- Method (a) Look up area in the Standard Normal Distribution Table equal to 0.495, the Closest is 2.58. So

- Method (b) Use the last line in the t Distribution Table for one tailed test, and find
 .
.
- Method (a) Look up area in the Standard Normal Distribution Table equal to 0.495, the Closest
So the critical area is that where  and the critical value is .
and the critical value is .
▢
One final note on setting up the hypotheses. When setting up the hypotheses and , one of the two alternatives will be the claim (what the problem says you really want to test). As mentioned before, a good experimental design will have as the claim. But this may not always be possible to arrange (especially in tests of assumptions). So many of the exercises in the text and assignments will have as the claim.
- So called not because it is confusing but because you are never 100
 sure which decision is correct. ↵
sure which decision is correct. ↵
